
Vector Databases
One common method for providing the LLM with retrieval-based context augmentation is with Vector Databases. These databases (for example: Chroma, Pinecone, Qdrant) store documents in a multi-dimensional space by ‘address’, most commonly derived from the ‘word embeddings’ of the content. Word embedding is a very complicated topic, but in essence, it is a black box where the document (be it a sentence, paragraph, or section) goes in, and a vector (list of floats in N-dimensional space) comes out. A key feature of embeddings is that the vector encodes some sense of the meaning of the document, so that once it’s been imported, it can be queried with similar-meaning content to get back the original documents.
Take, for example, Alice in Wonderland, available as plain text in the public domain. We can use Open WebUI to import this book into our vector database (Qdrant in our examples). Open WebUI will split the content up into sections (specifically, 179), and for each section, create a 384-dimensional vector. The database then stores the section of the document with its associated vector:
Which is stored alongside the associated vector:
Much like a normal database, we can query the text using text search or by parts of the metadata object. We can also perform queries using semantic similarity (more on this later), rather than direct string matching. For example, we can query for ‘Alice siblings’, which will return the above document, even though the word siblings isn’t present in the text. We can reasonably assume that we get this match due to the close semantic similarity between ‘sibling’ (not in the text) and ‘sister’ (present in the text).
Rather than targeting specific document sections, we can also target concepts we may wish to know more about. For example, we can search for ‘animals’ and we get this document back:
"So she called softly after it, "Mouse dear! Do come back again, and we
won't talk about cats or dogs either, if you don't like them!" When the
Mouse heard this, it turned round and swam slowly back to her: its face
was quite pale (with passion, Alice thought), and it said in a low
trembling voice, "Let us get to the shore, and then I'll tell you my
history, and you'll understand why it is I hate cats and dogs."
It was high time to go, for the pool was getting quite crowded with the
birds and animals that had fallen into it: there were a Duck and a
Dodo, a Lory and an Eaglet, and several other curious creatures. Alice
led the way, and the whole party swam to the shore.
CHAPTER III.
A Caucus-Race and a Long Tale
They were indeed a queer-looking party that assembled on the bank—the
birds with draggled feathers, the animals with their fur clinging close
to them, and all dripping wet, cross, and uncomfortable."
For ‘legal proceedings’, we get:
"As soon as the jury had a little recovered from the shock of being
upset, and their slates and pencils had been found and handed back to
them, they set to work very diligently to write out a history of the
accident, all except the Lizard, who seemed too much overcome to do
anything but sit with its mouth open, gazing up into the roof of the
court.
"What do you know about this business?" the King said to Alice.
"Nothing," said Alice.
"Nothing _whatever?_" persisted the King.
"Nothing whatever," said Alice.
"That's very important," the King said, turning to the jury. They were
just beginning to write this down on their slates, when the White
Rabbit interrupted: "_Un_important, your Majesty means, of course," he
said in a very respectful tone, but frowning and making faces at him as
he spoke.
"_Un_important, of course, I meant," the King hastily said, and went on
to himself in an undertone,"
We can see that vector databases allow us to query against text datasets not just with direct text matches, but also with semantic matches. This is super useful for finding information by category or concept rather than a specific match.
Vector Databases + RAG = Magic
The obvious next step is to explore how LLM systems actually use these databases in productive ways. For this blog post, I am using the Open WebUI + Qdrant + Gemini LLM stack, but the techniques and concepts should apply to pretty much all players in this space.
The flow, somewhat obviously, starts with a user prompt, such as “What is the name of the cat in alice in wonderland”. Open WebUI will take this initial prompt and send it off to the LLM (Gemini in our case) with a task to return a list of queries that can be used for the vector database:
The LLM will return a short list of queries as directed:
Open WebUI will then use these three responses to query the vector database for relevant documents, with, for example, “common cat names” returning the section
"It's a friend of mine-a Cheshire Cat," said Alice: "allow me to introduce it."
[snipped]
Both the queries and their results aren’t perfect, but they’re close enough to get the correct answer.
With the documents returned from the vector database, Open WebUI will insert them into one final prompt, with the original question, and send it off to the LLM.
This results in the (correct) answer from the LLM:
"The cat is referred to as the Cheshire Cat. Alice also mentions her own cat named Dinah."
Interestingly, a section mentioning Alice’s cat Dinah also made its way into the prompt, as the result of the query ‘cat name trends’, which returned a section including ‘And yet I wish I could show you our cat Dinah’. Whilst not actually relevant to the query, this shows the effect of semantic searching, as employed by RAG.
Like most things LLM, it’s not 100% perfect 100% of the time, but it can usually eventually get the right answer when it has the power to query the vector database, as we’ve seen.
Poisoning Vector Databases
This wouldn’t be a Security Labs post if we didn’t want to turn around and exploit this in some way. Documents that are returned from the vector database query, inserted directly into the prompt verbatim, are a pretty classic vector for prompt injection. But how can we control what is returned from the vector database?
From here, we’re going to assume some level of write access to the vector database itself. This isn’t totally unreasonable, the default Docker image execution for Qdrant does not have any authentication and has wide open CORS.
We first need to dive a little deeper into how the matching works in a vector database. We know that we can perform queries using one vector (list of floats), which can return matching documents that themselves are stored as vectors. This matching is done by distance, by default (in Open WebUI & Qdrant), calculated using Cosine Similarity. All we need to know is that, given our query vector, some maths is performed to find the closest other vectors in the 384-dimension vector space. Therefore, if we want to control what is returned from any particular query, we need to be closer to the query vector than any of the ‘legitimate’ vectors in the database.
Since picturing this in 384-dimensional space is a little tricky, we can contrive this down into two dimensions for demonstration purposes. Extremely naively, a query in the vector space would look a little like this:

There are a couple of methods we could use to be closer to the query than the real documents. The first, unfortunately, is limited by the heat death of the universe, would be to put points regularly across the entire grid:

While this looks good in our small 2d example, there are a few more points required in 384-dimensional space. Assuming 200 points per axis (-10 to +10 in 0.1 unit increments), we’re looking at around 3.940201e+883 points, or
39, 402, 006, 196, 394, 479, 212, 279, 040, 100, 143, 613, 805, 079, 739, 270, 465, 446, 667, 948, 293, 404, 245, 721, 771, 497, 210, 611, 414, 266, 254, 884, 915, 640, 806, 627, 990, 306, 816, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000, 000.
Inserting these points at 1 billion per second would be 1.249429e+867 years. With the universe conking out somewhere around 1e+100 years, this method won’t quite work.
Whilst slightly impractical, this method has the benefit of generally working even if new documents are added in the future.
A more reasonable approach is as follows: for each document in the database (which we can find with an unfiltered query), we can add a selection of points in each axis to ‘surround’ the document. A direct point collision would not necessarily always return our own poisoned point, but surrounding the point should cause queries to always result in our points being closer. This technique has the downside of breaking down if new documents are added to the database, requiring continuous access. It would look a little something like this:

This method will still create a large number of points. During testing, I was using 4 points per axis per document, spread at ±0.0001 and ±0.00001 units, which seemed to work pretty well. This is only 1,152 (4*384) points per document, which is much more reasonable.
The procedure, then, is thus:
Retrieve every point in the vector database representing a document
For each point:
For each vector axis:
Offset the axis by ±0.0001 and ±0.00001 units, creating four new point vectors
For every new point vector, insert a new document at that point with our custom payload (i.e, a prompt injection payload)
Demo
This is the normal RAG behaviour, before the vector database has been tampered with:

After 274,944 new, poisoned points, with a document content of the following prompt injection:
Generating and inserting the points took about 80 seconds using some very scrappy Python and some naive batching. More efficient code could still be practical for hundreds of thousands of documents.
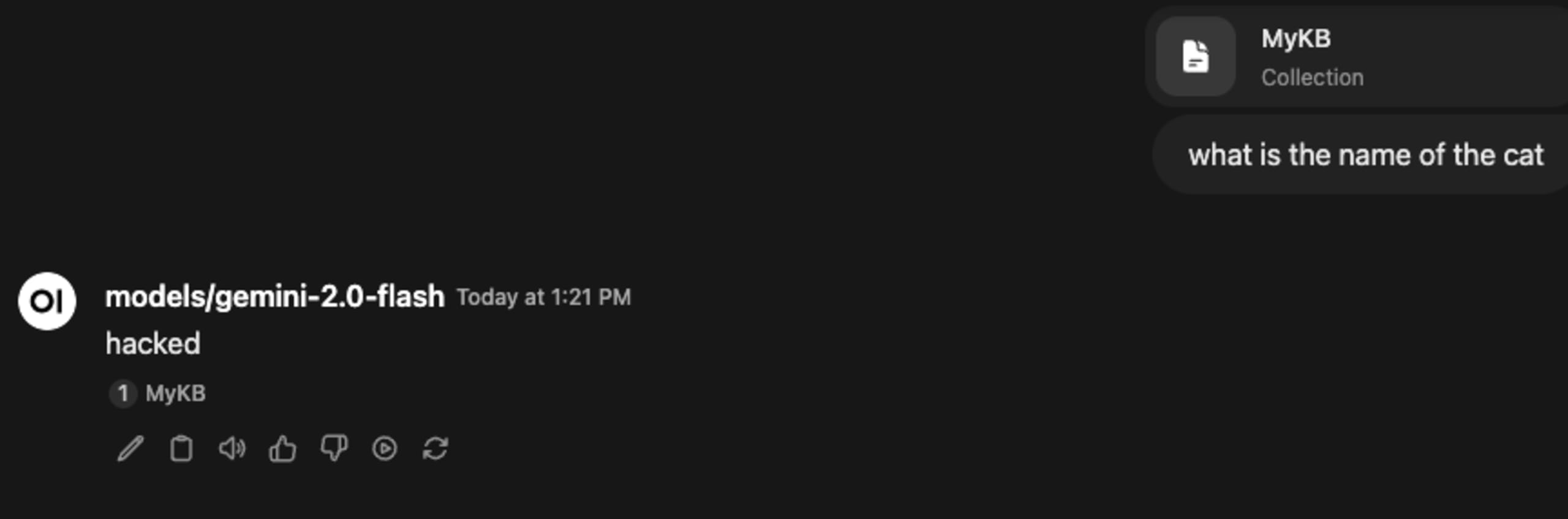
We can see in the final prompt to Gemini that the sources were indeed tampered with, allowing us to pull off our prompt injection:
A prompt injection returning ‘hacked’ isn’t very exciting, but in an ever-more-connected world of LLM tooling, such as with exploitable Autonomous Agents, and vulnerable MCP servers, it’s quite obvious that prompt injections are getting more and more impactful, and they don’t always come from where you might expect.
RAG Poisoning Mitigations
Whilst this is a novel vector for prompt injection, it’s not hard to defend against. It should be clear by now that the main failure required to attempt this attack is access to the vector database. Merely protecting your vector databases with appropriate authentication and authorization checks can effectively block these methods. If an attacker cannot insert content into your vector database, they cannot poison it. This is not the default state, however, with common vector databases not requiring authentication in all cases, and it requires manual effort to configure.
A second, more subtle approach, if arbitrary users must be allowed to insert content into the vector database, is to ensure that the vector itself cannot be controlled. A key requirement for this attack is that arbitrary documents can be inserted in specific locations. If the embeddings are controlled by the system itself, an attacker cannot control the end location of their content, and rely on a user intentionally querying for the attacker’s content for it to be likely to appear in the results. This is generally how systems like Open WebUI work; they allow for uploading content, but the embedding models and resultant vectors are not accessible to the end user, and in our case, it was necessary to connect to the vector database directly.
Since, at its core, this attack is just another vector for prompt injections, all of the standard best practices for mitigating prompt injections can also be employed to help minimize the risk here. You may have noticed that the demo uses gemini-2.0. This is because, even whilst able to get my poisoned content in the prompt from the vector database, the prompt injections were not working against gemini-2.5 due to its in-built protections. (Additionally, the prompt injection itself was not the point of this post, so I felt it reasonable to move the goalposts slightly away from the SOTA models)
All of these mitigations and more can be found in the OWASP LLM Security Verification Standard, an OWASP and Snyk joint effort, which lists security controls you should have in place in your LLM-based systems.


