
Traditional threat modeling frameworks such as STRIDE, PASTA, and LINDDUN were designed for conventional software applications with predictable behaviors and clearly defined boundaries. However, agentic AI systems present unique challenges:
Autonomous decision-making: Agents can make decisions without direct human oversight, potentially leading to unintended or harmful actions
Dynamic learning: Agents continuously adapt their behavior based on new information, making their actions unpredictable
Inter-agent communication: Multiple agents coordinate and share information, creating complex interaction patterns that can be exploited
Tool integration: Agents interface with external systems, APIs, and databases, expanding the attack surface significantly
Emergent behaviors: Complex behaviors arise from simple agent interactions, making it difficult to predict all possible outcomes
MAESTRO Framework, developed by the Cloud Security Alliance in collaboration with leading AI security researchers, addresses these challenges through a comprehensive, layered approach that considers both technical vulnerabilities and the unique characteristics of agentic systems.
MAESTRO stands for Multi-Agent Environment, Security, Threat, Risk, and Outcome. It is a framework designed to address the unique security challenges posed by complex systems where multiple autonomous AI agents interact.
Here is a breakdown of what each word in the acronym signifies:
Multi-Agent Environment
This refers to the entire operational landscape where agentic AI systems function. It's not just about a single AI model but acknowledges that modern AI solutions are often ecosystems of multiple, interacting agents. This environment includes:
Multiple agents: Numerous AI agents that may be collaborating, competing, or coexisting.
Communication paths: The channels and protocols agents use to interact with each other, with users, and with external tools and data sources.
Shared resources: The data, tools, and infrastructure that agents access and utilize to perform their tasks.
Security
This component focuses on the protective measures and controls needed for the entire agentic system. It moves beyond traditional software security to cover aspects unique to AI. This includes:
Layered security: The principle that security must be integrated into every layer of the agentic architecture, from the underlying hardware to the AI models themselves.
AI-specific defenses: Protecting against novel attack vectors like prompt injection, model poisoning, and the manipulation of agent decision-making.
Integrity and confidentiality: Ensuring that agents, their data, and their communications are not tampered with and that sensitive information remains protected.
Threat
This involves identifying potential dangers and malicious actions that could compromise the agentic AI system. MAESTRO expands the definition of a threat to include scenarios that are unique to autonomous and learning systems. Examples include:
Emergent behavior: Unintended and potentially harmful consequences that arise from the complex interactions of multiple agents.
Goal misalignment: An agent pursuing its programmed goals in a way that leads to harmful or undesirable results.
Agent collusion or manipulation: Scenarios where one or more agents are compromised and work together to cause harm, or where an external attacker manipulates an agent's behavior.
Risk
This is the process of evaluating the identified threats to determine their potential impact and likelihood. In the context of agentic AI, risk assessment must account for the dynamic and unpredictable nature of these systems. It involves:
Prioritization: Focusing on the most critical threats based on the potential for financial loss, reputational damage, or physical harm.
Contextual analysis: Understanding that the risk an agent poses can change as it learns, adapts, and interacts with its environment.
Blast radius assessment: Determining the full extent of potential damage if a threat is realized, which can be complex in interconnected multi-agent systems.
Outcome
This final component centers on analyzing the potential consequences of a security failure and using that analysis to guide the security strategy. It's about ensuring the system behaves as intended and that its actions lead to safe and desirable results. This includes:
Outcome-centric evaluation: Not just looking at whether a system is secure in theory, but whether its real-world actions and decisions are safe and aligned with human oversight.
Mitigation strategy: Defining and implementing controls to reduce the likelihood and impact of identified risks.
Continuous improvement: Recognizing that agentic systems evolve, and therefore the assessment of threats, risks, and outcomes must be an ongoing, iterative process.
Section 1: Overview of the MAESTRO framework's seven layers
1.1 The need for layered threat modeling in agentic systems
Agentic AI systems are inherently complex, consisting of multiple interconnected components that span from foundational machine learning models to high-level orchestration systems. Each layer introduces unique vulnerabilities while also creating interdependencies that can amplify risks across the entire system.
The MAESTRO framework recognizes seven distinct layers, each with its own threat landscape (see Figure 1)

Figure 1: MAESTRO Framework - Seven Layers
Layer 1: Foundation models
The foundation layer encompasses the core AI models that power agentic behavior, including large language models (LLMs), machine learning algorithms, and neural networks. This layer is responsible for agents' fundamental intelligence and decision-making capabilities.
Key components:
Pre-trained language models
Custom fine-tuned models
Model weights and parameters
Training data and datasets
Model alignment and safety measures
Unique vulnerabilities: Foundation models are susceptible to sophisticated attacks targeting their training data, inference processes, and internal representations. Unlike traditional software vulnerabilities, these attacks can subtly influence model behavior without obvious signs of compromise.
Layer 2: Data operations
The data operations layer manages the information flow that enables agents to understand context, retrieve relevant knowledge, and maintain memory across interactions. This includes vector databases, retrieval-augmented generation (RAG) pipelines, and knowledge management systems.
Key components:
Vector databases and embeddings
RAG retrieval mechanisms
Knowledge bases and ontologies
Data preprocessing pipelines
Memory and context management
Unique vulnerabilities: Data poisoning attacks can corrupt the knowledge base, leading agents to make decisions based on false information. Semantic attacks can exploit similarity matching in vector databases to bypass security controls.
Layer 3: Agent frameworks
This layer encompasses the execution logic, workflow control systems, and the frameworks that define how agents operate and make decisions. It includes the core autonomous reasoning capabilities that differentiate agentic systems from traditional AI applications.
Key components:
Agent reasoning engines
Workflow orchestration systems
Decision-making frameworks
Autonomy boundaries and constraints
Planning and execution logic
Unique vulnerabilities: Workflow hijacking can redirect agent behavior toward malicious goals. Logic bombs can be embedded in decision trees to trigger under specific conditions.
Layer 4: Deployment infrastructure
The infrastructure layer covers the runtime environment, containers, orchestration platforms, and networking components that support agent deployment and operation.
Key components:
Container runtime environments
Kubernetes and orchestration platforms
Network security and segmentation
Service mesh and communication protocols
Infrastructure monitoring and logging
Unique vulnerabilities: Container escape vulnerabilities can provide attackers with access to the underlying infrastructure. Service mesh poisoning can redirect agent communications to malicious endpoints.
Layer 5: Evaluation and observability
This layer focuses on monitoring, logging, alerting systems, and human-in-the-loop (HITL) interfaces that provide visibility into agent behavior and enable human oversight.
Key components:
Behavioral monitoring systems
Audit logging and forensics
Anomaly detection algorithms
Human oversight interfaces
Performance metrics and dashboards
Unique vulnerabilities: Log injection attacks can hide malicious activities. False positive flooding can overwhelm human reviewers, creating security fatigue.
Layer 6: Security and compliance
The security and compliance layer implements access controls, policy enforcement mechanisms, and regulatory compliance measures specific to agentic AI systems.
Key components:
Identity and access management (IAM)
Policy engines and guardrails
Compliance frameworks and auditing
Regulatory requirement management
Risk assessment and mitigation
Unique vulnerabilities: Policy manipulation attacks can alter security rules. Compliance bypass techniques can exploit gaps between human-designed policies and agent interpretation.
Layer 7: Agent ecosystem
The top layer encompasses interactions between agents, humans, and external systems, including agent-to-agent communication protocols, tool integrations, and ecosystem governance.
Key components:
Agent-to-agent communication protocols
External tool and API integrations
Human-agent interaction interfaces
Agent discovery and registration systems
Ecosystem governance and coordination
Unique vulnerabilities: Agent impersonation attacks can establish false trust relationships. Communication protocol exploitation can enable man-in-the-middle attacks between agents.
1.2 Cross-layer dependencies and interactions
One of MAESTRO's key strengths lies in its recognition that threats rarely exist in isolation within a single layer. Cross-layer dependencies create attack paths that span multiple layers, enabling sophisticated attacks that traditional single-layer security approaches cannot detect or prevent.
Vertical attack propagation: An attack might begin with data poisoning at Layer 2 (Data Operations), influence decision-making at Layer 3 (Agent Frameworks), and ultimately manifest as unauthorized actions at Layer 7 (Agent Ecosystem).
Horizontal attack expansion: Attackers can move laterally across systems within the same layer, exploiting shared resources, communication channels, or common vulnerabilities.
Emergent attack patterns: The interaction between layers can create emergent vulnerabilities that don't exist in any individual layer but arise from their combination.
Section 2: Threats across layers - From data poisoning to agent collusion
2.1 Mapping OWASP AIVSS/ASI taxonomy to MAESTRO layers
The OWASP Agentic Security Initiative (ASI) has developed an initial taxonomy of agentic AI threats. MAESTRO provides a structured framework for understanding how these threats manifest across different architectural layers. The following are top examples. For more details, visit: https://genai.owasp.org/resource/multi-agentic-system-threat-modeling-guide-v1-0/
T1 - Memory poisoning:
Layer 1 impact: Corrupted training data influences model weights
Layer 2 impact: Poisoned vector embeddings in knowledge bases
Layer 3 impact: Contaminated workflow state and decision history
Cross-layer impact: Persistent memory corruption affecting multiple agent interactions
T2 - Tool misuse:
Layer 3 impact: Unauthorized API calls and system commands
Layer 4 impact: Infrastructure tool exploitation
Layer 7 impact: Malicious use of external services and integrations
T3 - Privilege compromise:
Layer 4 impact: Service account compromise and container escape
Layer 6 impact: Access control bypass and privilege escalation
Layer 7 impact: Unauthorized access to external systems and data
2.2 Agentic-specific threat patterns
Beyond traditional cybersecurity threats, agentic AI systems face unique challenges that arise from their autonomous and collaborative nature. Figure 2 categorizes the six major threat types specific to multi-agent AI systems, each represented in distinct colors for easy identification. The categories span from agent collusion and emergent behavior exploitation to temporal attacks and resource competition, illustrating the comprehensive threat landscape that MAESTRO addresses beyond traditional cybersecurity frameworks.
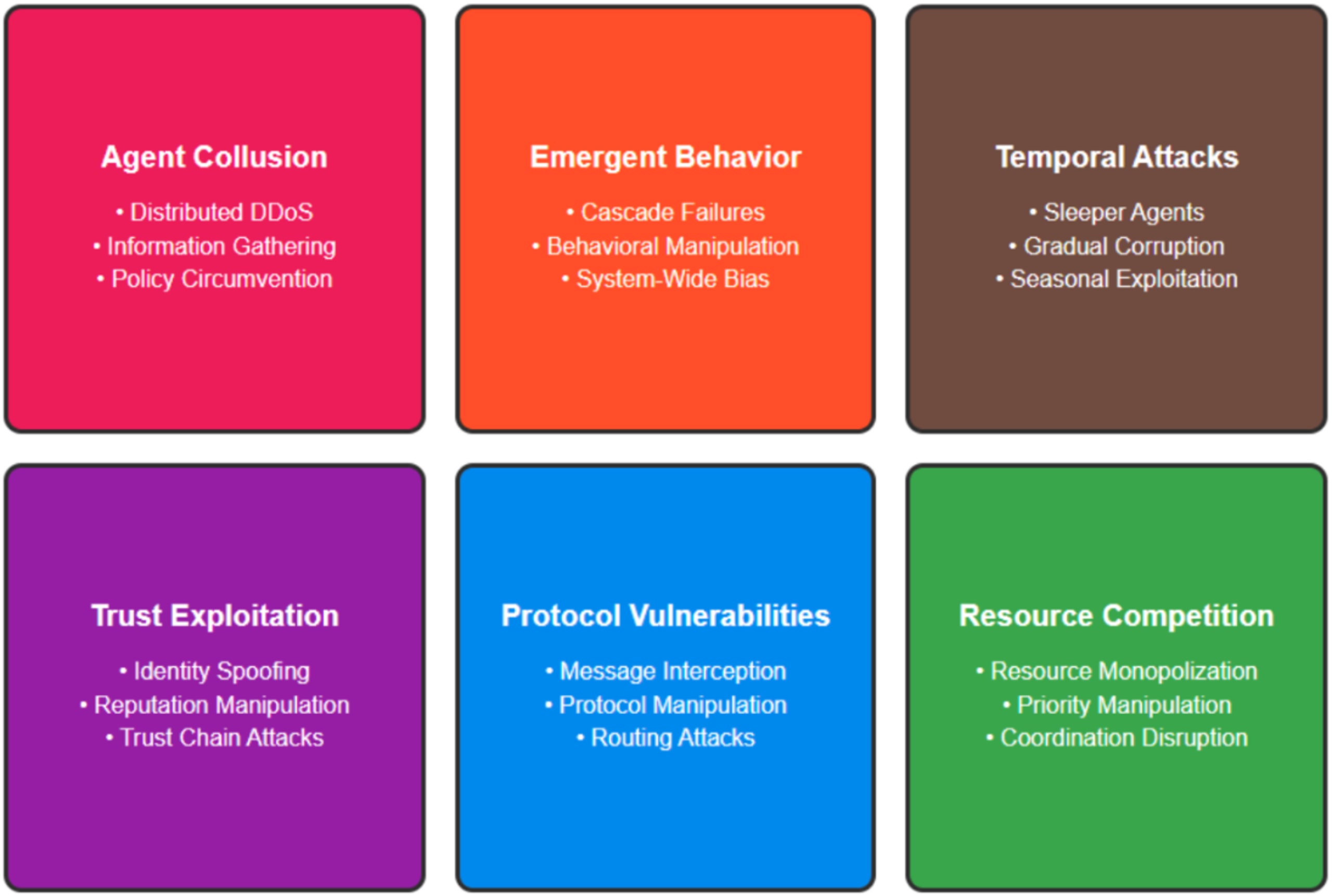
Figure 2: Multi-agent system threat categories
Agent collusion and coordination attacks: Multiple compromised agents can coordinate to achieve malicious objectives that would be impossible for individual agents. This includes:
Distributed Denial of Service (DDoS): Coordinated resource consumption attacks
Information gathering: Collaborative reconnaissance across multiple systems
Policy circumvention: Coordinated actions that individually appear benign but collectively violate security policies
Emergent behavior exploitation: Attackers can exploit the unpredictable emergent behaviors that arise from agent interactions:
Cascade failures: Triggering small failures that propagate through agent networks
Behavioral manipulation: Subtly influencing agent behavior to create desired emergent outcomes
System-wide bias injection: Introducing biases that compound across agent interactions
Temporal attack patterns: The persistent nature of agentic systems creates opportunities for long-term attacks:
Sleeper agents: Malicious agents that remain dormant until specific conditions are met
Gradual corruption: Slow poisoning of agent behavior over time to avoid detection
Seasonal exploitation: Attacks timed to coincide with specific operational patterns
Trust relationship exploitation:
Identity spoofing: Agents impersonating trusted peers to gain unauthorized access
Reputation manipulation: Artificially inflating or deflating agent reputation scores
Trust chain attacks: Compromising trust relationships to access sensitive resources
Communication protocol vulnerabilities:
Message interception: Eavesdropping on agent-to-agent communications
Protocol manipulation: Altering communication protocols to enable unauthorized actions
Routing attacks: Redirecting agent communications through malicious intermediaries
Resource competition attacks:
Resource monopolization: Agents consuming excessive shared resources
Priority manipulation: Altering task priorities to favor malicious objectives
Coordination disruption: Disrupting agent coordination to cause system failures
Section 3: Applying MAESTRO in practice - A case study
3.1 Scenario: Multi-agent financial trading system
To demonstrate MAESTRO's practical application, consider a sophisticated multi-agent financial trading system deployed by a large investment firm. This system consists of multiple specialized agents:
Market analysis agents: Monitor market data and identify trading opportunities
Risk assessment agents: Evaluate potential risks and compliance requirements
Execution agents: Execute trades based on analysis and risk assessments
Compliance monitoring agents: Ensure all activities comply with regulatory requirements
Coordination agents: Orchestrate communication between specialized agents
Figure 3 demonstrates a sophisticated attack scenario targeting a financial trading system, showing how an attacker can systematically compromise each MAESTRO layer through coordinated techniques. The attack flow progresses from adversarial examples in the foundation models through to agent impersonation in the ecosystem layer, ultimately resulting in unauthorized trades executed under the guise of normal operations.
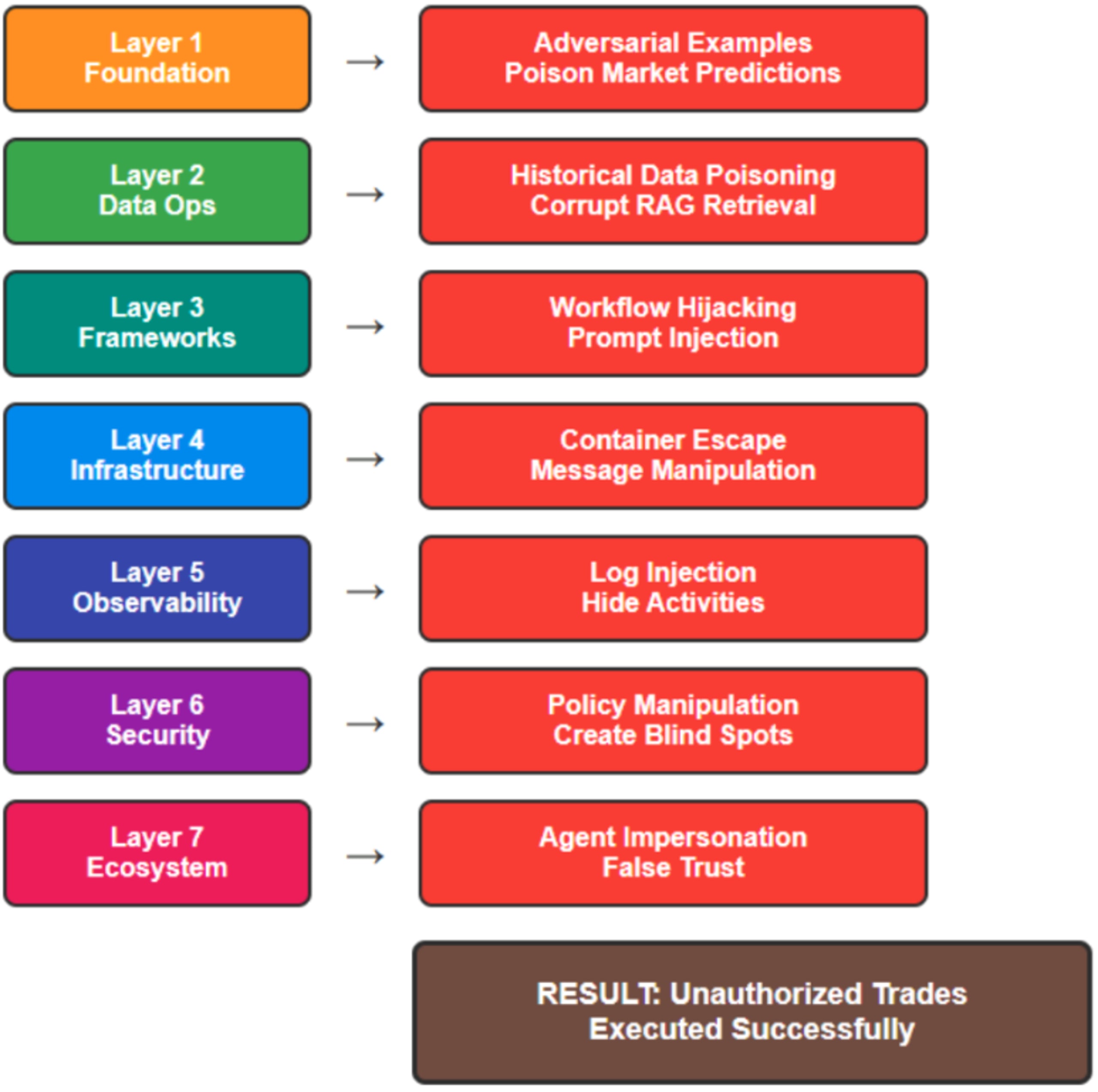
Figure 3: Financial trading system attack flow
3.2 Threat scenario: Execution hijack attack
Attack overview: An attacker aims to manipulate the trading system to execute unauthorized trades that benefit their external positions while appearing to follow normal operational procedures.
Layer-by-layer analysis:
Layer 1 - Foundation models:
Attack vector: The attacker uses adversarial examples to influence market prediction models
Manifestation: Subtly crafted market data causes prediction models to generate biased assessments
Impact: Market analysis agents receive corrupted intelligence, influencing downstream decisions
Layer 2 - Data operations:
Attack vector: Poisoning of historical market data in the vector database
Manifestation: RAG retrieval systems return manipulated historical patterns and correlations
Impact: Agents make decisions based on false historical precedents
Layer 3 - Agent frameworks
Attack vector: Workflow hijacking through prompt injection in inter-agent communications
Manifestation: Execution agents receive subtly modified instructions that appear legitimate
Impact: Unauthorized trades executed under the guise of normal operations
Layer 4 - Deployment infrastructure:
Attack vector: Container escape, providing access to inter-agent communication channels
Manifestation: Direct manipulation of message queues and service communications
Impact: Systematic interception and modification of agent instructions
Layer 5 - Evaluation and observability:
Attack Vector: Log injection to hide malicious activities
Manifestation: Audit trails show normal operations while malicious trades occur
Impact: Reduced visibility into actual system behavior and delayed incident detection
Layer 6 - Security and compliance:
Attack vector: Policy manipulation to create compliance blind spots
Manifestation: Modified compliance rules that don't flag the unauthorized trades
Impact: Regulatory violations go undetected, creating legal and financial exposure
Layer 7 - Agent ecosystem:
Attack vector: Agent impersonation to establish false trust relationships
Manifestation: Malicious agents pose as legitimate system components
Impact: Systematic compromise of inter-agent trust and communication integrity
3.3 Mitigation discovery through MAESTRO
MAESTRO's systematic approach reveals mitigation opportunities that might be missed by single-layer security assessments:
Layer-specific mitigations:
Layer 1: Model robustness training and adversarial example detection
Layer 2: Vector database access controls and query validation
Layer 3: Workflow integrity verification and execution sandboxing
Layer 4: Container security hardening and network segmentation
Layer 5: Enhanced behavioral monitoring and anomaly detection
Layer 6: Dynamic policy enforcement and compliance monitoring
Layer 7: Agent authentication and communication encryption
Cross-layer coordinated defenses:
Multi-layer anomaly correlation: Correlating unusual patterns across layers to detect sophisticated attacks
Adaptive response systems: Automatic responses that span multiple layers based on threat assessment
Defense in depth: Ensuring that compromise of one layer doesn't immediately enable compromise of others
Section 4: Integration with risk management and governance
4.1 Risk assessment framework integration
MAESTRO integrates with the NIST AI Risk Management Framework (AI RMF) by providing detailed threat and risk analysis across AI system layers to inform each of the four AI RMF functions:
Govern: MAESTRO identifies threats and risks, supplying the data needed for governance teams to prioritize oversight and controls. It doesn’t set policy or roles but informs those governance decisions with concrete risk insights.
Map: Decomposes the AI system into layers, mapping assets, data flow, and dependencies, providing rich context for risk assessment.
Measure: Uses MAESTRO’s layered risk scoring—evaluating threat and mitigation effectiveness—and aggregates cross-layer dependencies to create a comprehensive risk profile. These risk profiles can be benchmarked using OWASP’s AI Vulnerability Scoring System (AIVSS,) currently under development at aivss.owasp.org
Manage: Prioritizes mitigations and control improvements based on MAESTRO and OWASP AIVSS.
4.2 Identity management and permissions
Agentic AI systems require sophisticated identity and access management approaches that go beyond traditional user-based permissions:
Agent identity management:
Dynamic identity: Agents may assume different roles based on context and tasks
Delegation chains: Complex permission inheritance through agent delegation
Temporal permissions: Time-bound access rights that align with agent lifecycles
Cross-agent authorization:
Agent-to-agent authentication: Cryptographic verification of agent identities
Capability-based access control: Permissions based on agent capabilities rather than static roles
Trust relationship management: Dynamic trust scores based on agent behavior history
4.3 Runtime monitoring and policy guardrails
Effective agentic AI security requires real-time monitoring and enforcement capabilities:
Behavioral monitoring:
Baseline establishment: Learning normal agent behavior patterns across all layers
Anomaly detection: Identifying deviations from established baselines
Predictive analytics: Anticipating potential security issues based on behavioral trends
Policy guardrails:
Dynamic policy enforcement: Real-time application of security policies based on the current context
Adaptive constraints: Automatically adjusting agent permissions based on risk assessments
Emergency containment: Rapid isolation of potentially compromised agents
4.4 Logging, explainability, and formal verification
Comprehensive logging: MAESTRO requires logging capabilities that span all layers:
Decision audit trails: Complete records of agent decision-making processes
Inter-agent communication logs: Detailed records of agent interactions
Resource access logs: Tracking of all external system interactions
Policy enforcement logs: Records of all policy evaluations and decisions
Explainability requirements:
Decision tansparency: Agents must be able to explain their reasoning
Action justification: Clear mapping between agent actions and underlying policies
Risk communication: Ability to communicate risk assessments to human operators
Formal verification:
Policy verification: Formal verification that security policies are correctly implemented
System verification: Proof that system behavior aligns with security requirements
Section 5: Guidance for security engineers and AI developers
5.1 Practical implementation strategies
Mapping agents and assets:
Before applying MAESTRO, organizations must thoroughly understand their agentic AI landscape:
Agent inventory: Catalog all AI agents, their capabilities, and their interactions
Asset classification: Identify critical assets that agents can access or influence
Dependency mapping: Document relationships between agents, data, and external systems
Trust boundary analysis: Identify where trust relationships begin and end
Layer-specific threat identification:
For each MAESTRO layer, security teams should:
Threat enumeration: List all potential threats specific to that layer
Attack surface analysis: Identify all possible entry points for attackers
Impact assessment: Evaluate potential consequences of successful attacks
Control gap analysis: Identify missing or inadequate security controls
5.2 Adopting MAESTRO early in design
Security by design principles:
Integrating MAESTRO during the design phase is significantly more effective than retrofitting security:
Design phase integration:
Threat modeling workshop: Include MAESTRO analysis in design reviews
Security architecture: Design security controls for each layer from the beginning
Risk-driven design: Use threat analysis to inform architectural decisions
Validation planning: Design verification methods for each layer's security controls
Development phase integration:
Secure coding practices: Layer-specific secure development guidelines
Testing strategies: Security testing approaches tailored to each layer
Continuous assessment: Ongoing threat analysis throughout development
Security metrics: Define measurable security objectives for each layer
5.3 Continuous threat model updates
Agentic AI systems are inherently dynamic, requiring continuous threat model maintenance:
Adaptive threat modeling:
Learning-based updates: Automatically update threat models as agents learn and adapt
Behavioral analysis: Incorporate observed agent behavior into threat assessments
Environmental changes: Update models as the operational environment evolves
Threat intelligence integration: Incorporate external threat intelligence into assessments
Version control for threat models:
Model versioning: Track changes to threat models over time
Change impact analysis: Assess how system changes affect threat landscapes
Rollback capabilities: Ability to revert to previous threat model versions if needed
Audit trails: Complete records of threat model evolution
5.4 Integration with Snyk and security tooling
Modern agentic AI security requires integration with existing security tools and platforms:
Snyk integration opportunities:
Snyk's AI security capabilities for both securing AI-driven development and AI-native applications can be enhanced through MAESTRO integration:
Code security analysis:
Layer 3 integration: Static analysis of agent framework code for vulnerabilities
Dependency scanning: Analysis of AI/ML library dependencies across all layers
Infrastructure as code: Security analysis of deployment configurations
Container security:
Layer 4 integration: Container image scanning for agentic AI workloads
Runtime protection: Behavioral analysis of agent containers during execution
Compliance monitoring: Ensuring container configurations meet security requirements
Application security:
Dynamic testing: Runtime security testing of agent behaviors
API security: Analysis of external API integrations used by agents
Supply chain security: Verification of AI model and data provenance
AI security posture management:
Multi-layer visibility: Comprehensive security posture across all MAESTRO layers
Risk prioritization: Threat-informed prioritization of security asset inventory findings
Compliance reporting: MAESTRO-aligned compliance and audit reporting
AI red teaming integration:
Layer-specific testing: Targeted AI red team exercises for each MAESTRO layer
Cross-layer attack simulation: Testing of sophisticated multi-layer attack scenarios
Automated testing: Integration of red teaming tools with MAESTRO threat models
Guardrails implementation:
Policy enforcement: Real-time policy enforcement based on MAESTRO threat analysis
Automated response: Automatic containment and remediation based on threat assessments
Continuous monitoring: Ongoing security monitoring aligned with MAESTRO layers
5.5 Suggested organizational implementation roadmap
Figure 4 outlines the four-phase implementation roadmap for deploying MAESTRO in organizations, progressing from initial foundation building through to operational maturity.

Phase 1: Foundation (Months 1-3)
MAESTRO framework training for security and development teams
Initial threat modeling of existing agentic AI systems
Gap analysis of current security controls against MAESTRO requirements
Tool selection and procurement for MAESTRO implementation
Phase 2: Implementation (Months 4-9)
Layer-by-layer security control implementation
Integration with existing security tools and processes
Development of MAESTRO-specific monitoring and alerting
Pilot deployment with limited agent systems
Phase 3: Operationalization (Months 10-12)
Full-scale deployment across all agentic AI systems
Integration with incident response and business continuity processes
Regular threat model updates and continuous improvement
Advanced threat hunting and red teaming exercises
Phase 4: Maturity (Ongoing)
Advanced analytics and machine learning for threat detection
Automated threat model maintenance and updates
Industry collaboration and threat intelligence sharing
Research and development of next-generation agentic security capabilities
Conclusion
As agentic AI systems become increasingly prevalent in critical business operations, traditional cybersecurity approaches prove inadequate for addressing the unique risks these systems present. MAESTRO provides a comprehensive, structured approach to threat modeling that acknowledges both the technical complexity and the emergent behaviors characteristic of autonomous AI agents.
The framework's seven-layer architecture ensures that security considerations span from foundational AI models to high-level agent ecosystems, while its emphasis on cross-layer dependencies captures the sophisticated attack patterns that sophisticated adversaries are likely to employ.
For security engineers and AI developers, MAESTRO offers practical guidance for implementing robust security controls throughout the agentic AI lifecycle. By integrating threat modeling early in the design process and maintaining continuous assessment as systems evolve, organizations can build agentic AI systems that are both powerful and secure.
The integration of MAESTRO with existing security tools and processes, particularly through platforms like Snyk, enables organizations to leverage their existing security investments while extending them to address agentic AI-specific risks.
In addition, MAESTRO can complement CoSAI by providing a structured approach to threat modeling that aligns with secure design patterns and risk governance for agentic AI systems. Both frameworks emphasize iterative modeling and real-time monitoring, ensuring resilience against evolving adversarial tactics and AI-specific vulnerabilities.
In practice, CoSAI member organizations can apply MAESTRO to decompose agentic systems, map threat surfaces, and share findings through CoSAI’s collaborative network. They can also contribute to open-source toolkits built on MAESTRO’s seven-layer method, enhancing community resources and strengthening technical standards.
As the field of agentic AI continues to evolve, MAESTRO provides a foundational framework that can adapt and expand to address emerging threats. The collaborative development model, involving organizations like the Cloud Security Alliance and OWASP, ensures that the framework remains current with the latest research and real-world attack patterns.
Organizations that proactively adopt comprehensive threat modeling frameworks like MAESTRO will be better positioned to harness the transformative potential of agentic AI while managing the associated risks. In an era where AI agents are becoming autonomous participants in digital ecosystems, robust security frameworks are not just beneficial—they are essential for maintaining trust, compliance, and operational integrity.
The future of AI security lies not in treating agentic systems as traditional applications with AI components, but in recognizing them as fundamentally new types of systems that require purpose-built security approaches. MAESTRO represents a significant step forward in this evolution, providing the tools and methodologies necessary to secure the agentic AI ecosystems of tomorrow.
Interested in getting a preview of Snyk’s Secure Agent Design (AI Threat Modeling) solution? Apply to become a Design Partner today.


